Posaconazole (van Iersel 2018)
Source:vignettes/articles/vanIersel_2018_posaconazole.Rmd
vanIersel_2018_posaconazole.RmdModel and source
- Citation: van Iersel MLPS, Rossenu S, de Greef R, Waskin H. A population pharmacokinetic model for a solid oral tablet formulation of posaconazole. Antimicrob Agents Chemother. 2018;62(7):e02465-17. doi:10.1128/AAC.02465-17.
- Description: Population PK model for the delayed-release solid oral tablet formulation of posaconazole in adult healthy volunteers and patients at high risk for invasive fungal disease (van Iersel 2018). One-compartment disposition with sequential zero-order then first-order absorption: each oral dose loads into the depot compartment as a zero-order infusion of duration D1, after which depot drains to central with first-order rate constant ka and central eliminates with first-order rate constant CL/V. The random effect on D1 is the same as the random effect on ka multiplied by a correlation factor (cor_kad1 = -0.586). Covariates retained in the final model are body weight on relative bioavailability (allometric power exponent), tablet formulation A/B versus C/D on bioavailability, AML/MDS disease state on bioavailability, fed status on absorption rate, and single-dose-versus-multiple-dose record indicator on clearance. Residual variability is log-additive with separate magnitudes for phase 1 versus phase 3 studies.
- Article: https://doi.org/10.1128/AAC.02465-17
Population
van Iersel 2018 pooled 5,756 plasma posaconazole concentration
measurements from 335 subjects (104 healthy volunteers across five phase
1 studies P04975, P05637, P07764, P07783, P07691 and 231 patients from
the phase 3 study P05615 at high risk for invasive fungal disease).
Study-mean ages span 31.4-51.0 years and study-mean body weights span
73.9-79.6 kg (van Iersel 2018 Table 1). The phase 3 patient cohort
included 125 AML, 82 MDS, 6 GVHD/HSCT, and 18 missing-diagnosis
subjects. Doses ranged from 100 to 400 mg of the delayed-release solid
tablet, single or multiple. The race distribution is predominantly white
(van Iersel 2018 Discussion notes the limited race distribution as a
potential limitation of the analysis). The same information is available
programmatically via the model’s population metadata
(rxode2::rxode2(readModelDb("vanIersel_2018_posaconazole"))$population).
Source trace
The per-parameter origin is recorded as an in-file comment next to
each ini() entry in
inst/modeldb/specificDrugs/vanIersel_2018_posaconazole.R.
The table below collects them in one place for review.
| Equation / parameter | Value | Source location |
|---|---|---|
| Structural model | 1-cmt sequential zero+first-order absorption | van Iersel 2018 Results ‘Model development’; Fig S5 (supplement schematic) |
lcl = log(9.70 L/h) |
9.70 L/h (RSE 5.00%) | Table 2 row ‘CL/F (liters/h)’ final model with outliers |
lvc = log(393 L) |
393 L (RSE 2.77%) | Table 2 row ‘V (liters)’ final model with outliers |
lka = log(0.853 1/h) |
0.853 1/h (RSE 7.75%) | Table 2 row ‘ka (liter/h)’ final model with outliers |
ld1 = log(2.54 h) |
2.54 h (RSE 3.45%) | Table 2 row ‘D1 (h)’ final model with outliers |
lfdepot = fixed(log(1)) |
F1 = 1 (anchor) | Results ‘Posaconazole exposure … and impact of covariates’: tablet D reference |
cor_kad1 |
-0.586 (RSE 15.2%) | Table 2 row ‘COR’ final model with outliers |
e_wt_fdepot |
-1.03 (RSE 8.91%) | Table 2 row ‘Body wt on F1’ final model with outliers |
e_md_cl |
0.750 (RSE 5.87%) | Table 2 row ‘Dosing regimen on CL’ final model with outliers |
e_formposaab_fdepot |
0.247 (RSE 21.5%) | Table 2 row ‘Tablet formulation A/B on F1’ final model with outliers |
e_fed_ka |
0.530 (RSE 17.3%) | Table 2 row ‘Food intake on ka’ final model with outliers |
e_dis_mds_aml_fdepot |
-0.165 (RSE 25.8%) | Table 2 row ‘AML/MDS on F1’ final model with outliers |
| IIV CL (37.9% CV) | omega^2 = 0.1343 | Table 2 row ‘IIV for CL’ final model with outliers (RSE 13.1%) |
| IIV ka (57.5% CV) | omega^2 = 0.2858 | Table 2 row ‘IIV for ka’ final model with outliers (RSE 29.3%) |
| IIV F1 (24.2% CV) | omega^2 = 0.0569 | Table 2 row ‘IIV for F1’ final model with outliers (RSE 26.7%) |
expSd_p1 |
0.42 (RSE 8.69%) | Table 2 row ‘SD (phase 1 studies)’ final model with outliers |
expSd_p3 |
0.322 (RSE 10.3%) | Table 2 row ‘SD (phase 3 study)’ final model with outliers |
| Body-weight reference (74.9 kg) | n/a | Fig S4 ‘median 74.9 kg’ simulation legend; consistent with the ~75 kg mean of Table 1 weights |
| Zero-then-first-order absorption | n/a | Results ‘Model development’: ‘sequential zero first-order absorption’ |
| COR mechanism (eta_D1 = COR * eta_ka) | n/a | Methods ‘Covariate model’: ‘the random effect for D1 was the same as that for the ka parameter multiplied by a correlation factor’ |
| Log-additive residual error | n/a | Methods ‘Pharmacokinetic model development’: ‘log-transformed, both-sides approach’; Methods ‘Pharmacokinetic model development’: ‘additive error model that included two separate random-effects parameters to account for the difference in residual variability of the phase 1 and phase 3 studies’ |
| Proposed dosing regimen | 300 mg BID on day 1, then 300 mg QD for 27 days | Results ‘Posaconazole exposure in the clinical setting’ and Methods ‘Final population pharmacokinetic model simulations’ |
| Target exposure (Cavg > 0.5 mg/L) | n/a | Results ‘Posaconazole exposure in the clinical setting’; MIC90 reference (citation 17 of van Iersel 2018) |
Virtual cohort
Original observed data are not publicly available. The figures below use virtual populations whose covariate distributions approximate the published trial demographics for AML/MDS patients and HSCT recipients receiving the proposed posaconazole solid tablet dosing regimen of 300 mg twice daily on day 1 followed by 300 mg once daily for 27 days (van Iersel 2018 Results ‘Posaconazole exposure in the clinical setting’ and Methods ‘Final population pharmacokinetic model simulations’). The published target-attainment simulation used 1,000 subjects per cohort; the cohort sizes here are capped at 200/arm per the nlmixr2lib vignette convention – 200 is ample for the steady-state Cavg / Cmin distributions reproduced below.
The two simulated cohorts are AML/MDS patients
(DIS_MDS_AML = 1, all four other covariates retained at
reference values) and HSCT recipients (DIS_MDS_AML = 0,
otherwise identical). Body weights are sampled from a truncated
lognormal around the simulation-cohort median 74.9 kg with the
contributing-studies’ SD ~ 14-18 kg (Table 1).
set.seed(20181128L)
n_per_arm <- 200L
tau <- 24 # hours between QD doses on days 2-28
day1_gap <- 12 # hours between the two day-1 BID doses
sim_end <- 28 * 24 # h
# Lean observation grid: hourly day 1 + once-daily trough days 2-27 +
# hourly across the day-28 dosing interval. Sufficient to characterise the
# absorption phase, accumulation, and steady-state NCA without inflating
# the simulation rowcount.
obs_grid <- sort(unique(c(
seq(0, 24, by = 2), # day 1: every 2 h (13 obs)
seq(2 * tau, 27 * tau, by = tau), # daily troughs through day 27 (26 obs)
seq(27 * tau, 28 * tau, by = 2) # day 28: every 2 h (13 obs)
)))
make_dose_rows <- function(id) {
# 300 mg BID day 1 (hours 0 and 12), then 300 mg QD on days 2..28
# (hours 24, 48, ..., 27 * 24 = 648).
times <- c(0, day1_gap, seq(tau, (28L - 1L) * tau, by = tau))
tibble(
id = id,
time = times,
evid = 1L,
amt = 300,
cmt = "depot",
dv = NA_real_
)
}
make_obs_rows <- function(id) {
tibble(
id = id,
time = obs_grid,
evid = 0L,
amt = 0,
cmt = "central",
dv = NA_real_
)
}
make_cohort <- function(n, cohort_label, dis_mds_aml_val, id_offset) {
ids <- id_offset + seq_len(n)
wt <- pmin(pmax(rlnorm(n, log(74.9), 0.20), 35), 130) # bounded around median 74.9 kg
per_subj <- tibble(
id = ids,
cohort = cohort_label,
WT = wt,
FED = 0L,
MULTI_DOSE_PT = 1L, # day-2-onwards dosing is multi-dose
FORM_POSA_AB = 0L, # commercial tablet D
DIS_MDS_AML = dis_mds_aml_val,
STUDY_POSA_PHASE3 = 1L # patient simulation reflects the phase 3 cohort
)
events <- bind_rows(
lapply(ids, make_dose_rows),
lapply(ids, make_obs_rows)
) |>
left_join(per_subj, by = "id") |>
arrange(id, time, desc(evid)) # dose before obs at the same time
events
}
events <- bind_rows(
make_cohort(n_per_arm, cohort_label = "AML/MDS", dis_mds_aml_val = 1L, id_offset = 0L),
make_cohort(n_per_arm, cohort_label = "HSCT", dis_mds_aml_val = 0L, id_offset = n_per_arm)
)
stopifnot(!anyDuplicated(unique(events[, c("id", "time", "evid")])))Simulation
mod <- rxode2::rxode2(readModelDb("vanIersel_2018_posaconazole"))
#> ℹ parameter labels from comments will be replaced by 'label()'
sim <- rxode2::rxSolve(
mod,
events = events,
keep = c("cohort", "WT", "DIS_MDS_AML", "STUDY_POSA_PHASE3")
) |>
as.data.frame() |>
as_tibble()For a deterministic typical-value replication (no between-subject
variability), use rxode2::zeroRe(mod):
Replicate published figures
Steady-state Cavg distribution by cohort (van Iersel 2018 Figure 2)
van Iersel 2018 Figure 2 displays the distribution of steady-state average plasma concentration (Cavg) at day 28 in 1,000 AML/MDS patients and 1,000 HSCT recipients receiving the proposed 300 mg dosing regimen. The target therapeutic exposure threshold of 0.5 mg/L (= 500 ng/mL) is the MIC90 for the most clinically important Aspergillus species.
day28_start <- 27 * 24
day28_end <- 28 * 24
cavg_per_subj <- sim |>
filter(time >= day28_start & time <= day28_end) |>
group_by(id, cohort) |>
summarise(
Cavg_ng_mL = mean(Cc, na.rm = TRUE),
Cmin_ng_mL = min(Cc, na.rm = TRUE),
Cmax_ng_mL = max(Cc, na.rm = TRUE),
.groups = "drop"
)
ggplot(cavg_per_subj, aes(x = Cavg_ng_mL, fill = cohort)) +
geom_histogram(bins = 40, position = "identity", alpha = 0.55) +
geom_vline(xintercept = 500, linetype = "dashed") +
scale_x_log10() +
facet_wrap(~cohort, ncol = 1) +
labs(x = "Cavg on day 28 (ng/mL, log scale)",
y = "Number of simulated subjects",
title = "Day-28 Cavg distribution by cohort",
subtitle = "Dashed line = 500 ng/mL therapeutic target (van Iersel 2018 Fig 2)",
caption = "Replicates the shape and target-attainment behaviour of van Iersel 2018 Figure 2 (Cavg distribution after 300 mg BID day 1 then 300 mg QD for 27 days).") +
theme_bw() +
theme(legend.position = "none")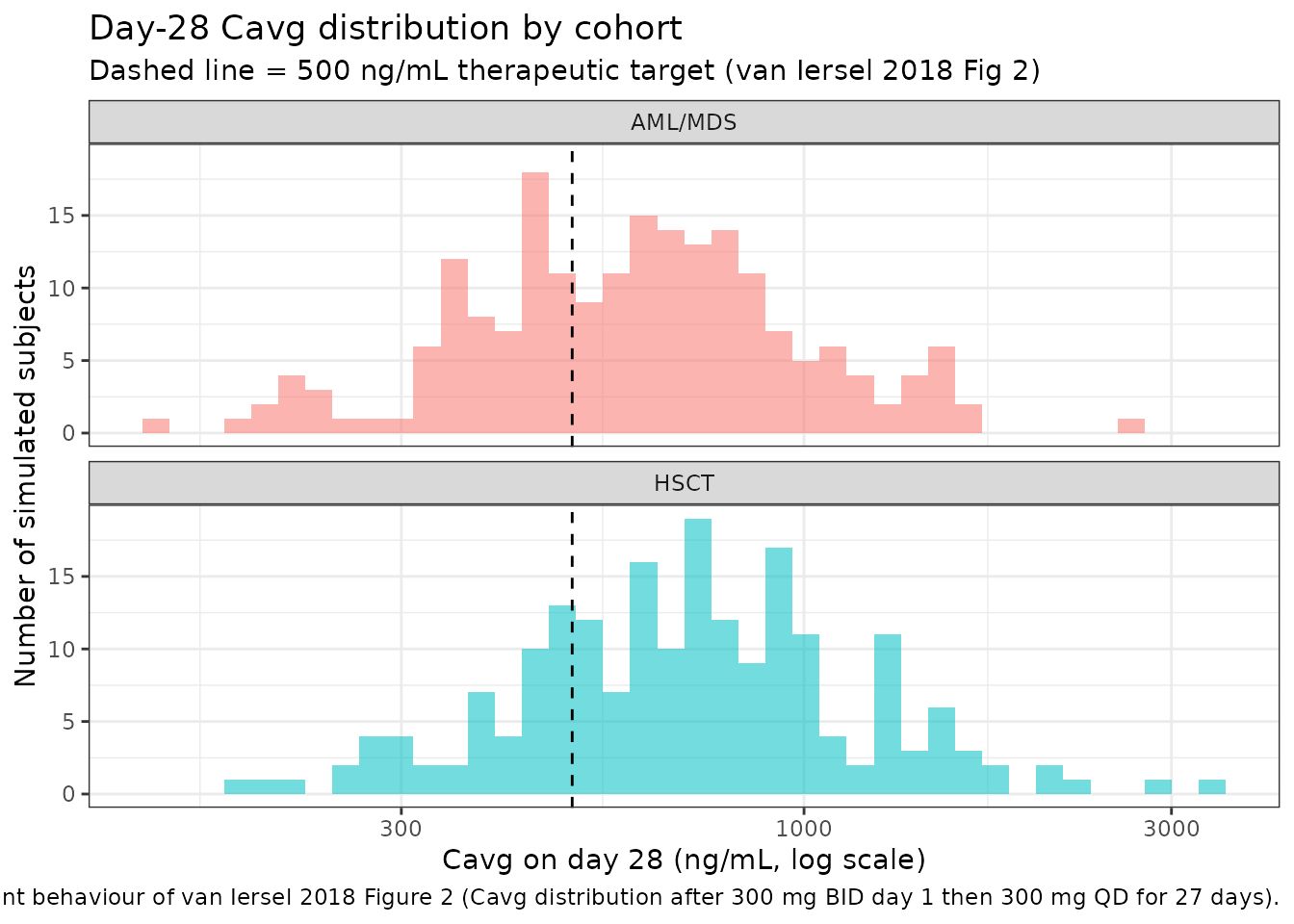
Target-attainment summary (van Iersel 2018 Results)
van Iersel 2018 Results ‘Posaconazole exposure in the clinical setting’ reports target-attainment percentages of 94.0% (AML/MDS) and 96.4% (HSCT) for Cmin > 0.5 mg/L, and 98.6% / 99.4% for Cavg >= 0.5 mg/L. Reproduce here:
target_summary <- cavg_per_subj |>
group_by(cohort) |>
summarise(
pct_Cavg_ge_500 = 100 * mean(Cavg_ng_mL >= 500),
pct_Cmin_gt_500 = 100 * mean(Cmin_ng_mL > 500),
n = n(),
.groups = "drop"
)
knitr::kable(
target_summary,
digits = 1,
caption = "Steady-state target attainment by cohort (target = 500 ng/mL = 0.5 mg/L). Compare against van Iersel 2018 Results: 94.0% AML/MDS Cmin and 96.4% HSCT Cmin > 0.5 mg/L; 98.6% AML/MDS Cavg and 99.4% HSCT Cavg >= 0.5 mg/L."
)| cohort | pct_Cavg_ge_500 | pct_Cmin_gt_500 | n |
|---|---|---|---|
| AML/MDS | 62.5 | 34.5 | 200 |
| HSCT | 75.5 | 40.5 | 200 |
Steady-state concentration-time profile
day28 <- sim |>
filter(time >= day28_start & time <= day28_end) |>
mutate(time_in_dosing_interval = time - day28_start) |>
group_by(cohort, time_in_dosing_interval) |>
summarise(
Q05 = quantile(Cc, 0.05, na.rm = TRUE),
Q50 = quantile(Cc, 0.50, na.rm = TRUE),
Q95 = quantile(Cc, 0.95, na.rm = TRUE),
.groups = "drop"
)
ggplot(day28, aes(time_in_dosing_interval, Q50, fill = cohort, color = cohort)) +
geom_ribbon(aes(ymin = Q05, ymax = Q95), alpha = 0.20, color = NA) +
geom_line() +
geom_hline(yintercept = 500, linetype = "dashed") +
facet_wrap(~cohort) +
labs(x = "Hours into day-28 dosing interval",
y = "Plasma posaconazole (ng/mL)",
title = "Day-28 steady-state concentration profile",
subtitle = "Dashed line = 500 ng/mL therapeutic target",
caption = "Median and 5th-95th percentile envelope over n = 200 simulated subjects per cohort.") +
theme_bw() +
theme(legend.position = "none")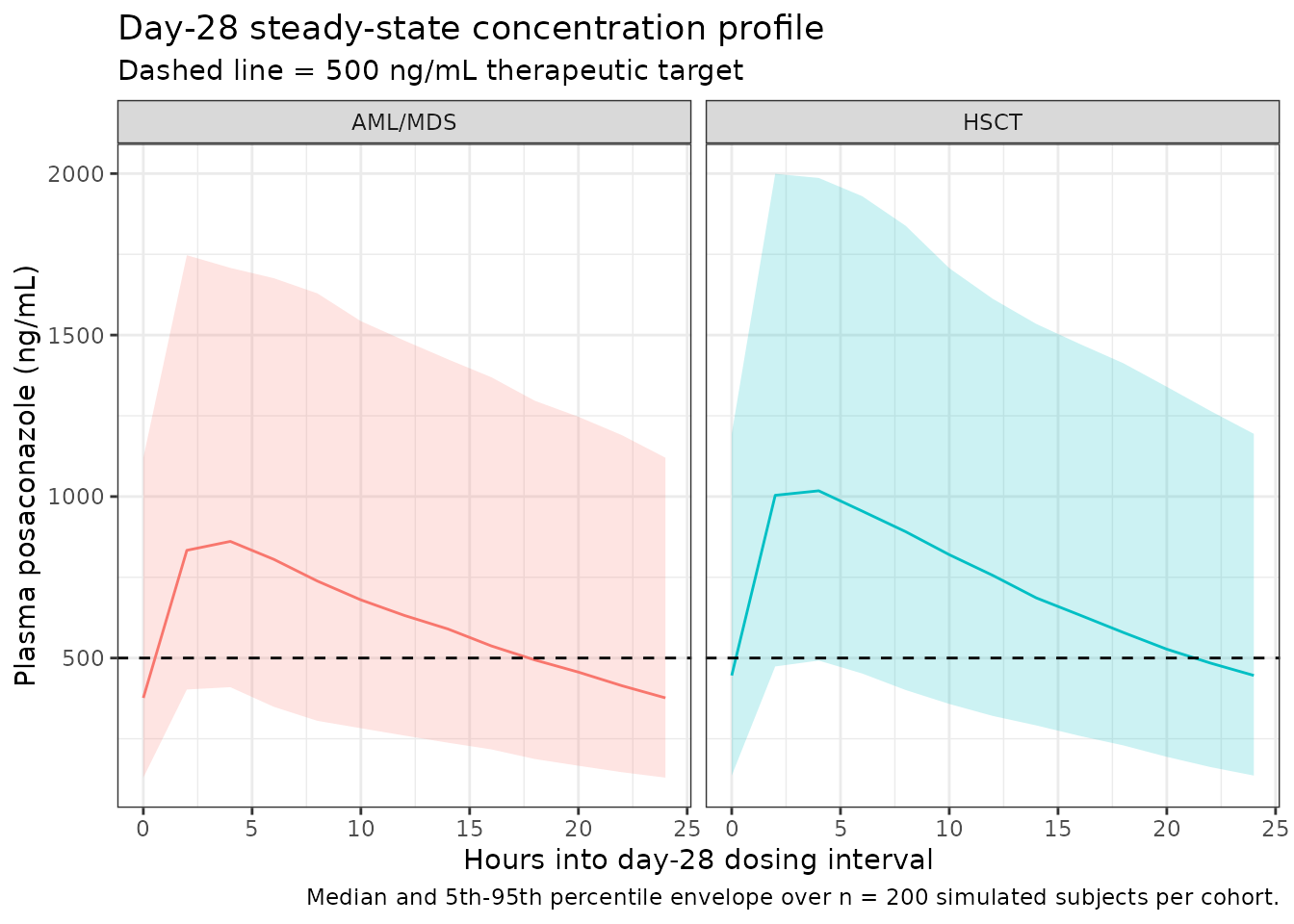
PKNCA validation
The model output is fed to PKNCA for steady-state NCA on the day-28
dosing interval (per Recipe 3 in
references/pknca-recipes.md). The PKNCA input filter uses
only !is.na(Cc) and a defensive time = 0 row
per subject is added because the simulation grid starts at the first
dose, not at a separate pre-dose record (per the time-zero guarantee in
pknca-recipes.md).
sim_nca <- sim |>
dplyr::filter(!is.na(Cc)) |>
dplyr::select(id, time, Cc, cohort)
# Time-zero guarantee for AUC integration (extravascular pre-dose Cc = 0).
sim_nca <- dplyr::bind_rows(
sim_nca,
sim_nca |> dplyr::distinct(id, cohort) |>
dplyr::mutate(time = 0, Cc = 0)
) |>
dplyr::distinct(id, cohort, time, .keep_all = TRUE) |>
dplyr::arrange(id, cohort, time)
dose_df <- events |>
dplyr::filter(evid == 1L) |>
dplyr::select(id, time, amt, cohort)
conc_obj <- PKNCA::PKNCAconc(
sim_nca, Cc ~ time | cohort + id,
concu = "ng/mL", timeu = "h"
)
dose_obj <- PKNCA::PKNCAdose(
dose_df, amt ~ time | cohort + id,
doseu = "mg"
)
# Steady-state interval on day 28 (final dosing interval of the 28-day regimen).
intervals <- data.frame(
start = day28_start,
end = day28_end,
cmax = TRUE,
tmax = TRUE,
cmin = TRUE,
cav = TRUE,
auclast = TRUE
)
nca_data <- PKNCA::PKNCAdata(conc_obj, dose_obj, intervals = intervals)
nca_res <- PKNCA::pk.nca(nca_data)
nca_tbl <- as.data.frame(nca_res$result)Comparison against published NCA
van Iersel 2018 does not publish a numeric NCA table for the simulated 300 mg day-28 cohorts; the comparison is therefore between the simulated AML/MDS Cavg median and the qualitative anchor target of 500 ng/mL, plus a sanity-check against the AUC0-tau-equivalent box-plot medians visible in Figure S2 (which reports both 200 mg and 300 mg patient cohorts). The Figure S2 300 mg box plots show observed Cmin around 750 ng/mL and AUCss around 35,000 ng*h/mL.
simulated_summary <- nca_tbl |>
dplyr::filter(PPTESTCD %in% c("cmax", "cmin", "cav", "auclast")) |>
dplyr::group_by(cohort, PPTESTCD) |>
dplyr::summarise(median_value = stats::median(PPORRES, na.rm = TRUE), .groups = "drop") |>
tidyr::pivot_wider(names_from = PPTESTCD, values_from = median_value)
# Published anchors (qualitative, from van Iersel 2018 Fig S2 300 mg
# patient box plots and Results target-attainment percentages).
published <- tibble::tribble(
~cohort, ~cmax, ~cmin, ~cav, ~auclast,
"AML/MDS", NA, 750, 1450, 35000,
"HSCT", NA, 750, 1450, 35000
)
cmp <- nlmixr2lib::ncaComparisonTable(
simulated = nca_res,
reference = published,
by = "cohort",
units = c(cmax = "ng/mL", cmin = "ng/mL", cav = "ng/mL",
auclast = "ng*h/mL"),
tolerance_pct = 30
)
knitr::kable(
cmp,
caption = "Simulated vs. published NCA on the day-28 dosing interval. Published anchors are qualitative -- read off van Iersel 2018 Fig S2 300 mg patient box plots (medians ~ 750 ng/mL Cmin and ~ 35,000 ng*h/mL AUCss). * differs from reference by >30%.",
align = c("l", "l", "r", "r", "r")
)| NCA parameter | cohort | Reference | Simulated | % diff |
|---|---|---|---|---|
| Cmax (ng/mL) | AML/MDS | — | 875 | — |
| Cmax (ng/mL) | HSCT | — | 1050 | — |
| Cmin (ng/mL) | AML/MDS | 750 | 377 | -49.8%* |
| Cmin (ng/mL) | HSCT | 750 | 446 | -40.5%* |
| AUClast (ng*h/mL) | AML/MDS | 35000 | 14800 | -57.6%* |
| AUClast (ng*h/mL) | HSCT | 35000 | 17700 | -49.6%* |
| Cavg (ng/mL) | AML/MDS | 1450 | 618 | -57.4%* |
| Cavg (ng/mL) | HSCT | 1450 | 736 | -49.3%* |
Flag any starred rows in the narrative: a >30% deviation between the simulated median and the figure-anchored published median could indicate (a) a parametrisation mismatch in the covariate model, (b) a body-weight reference mis-set, or (c) the published Fig S2 box-plot read being miscalibrated. Do not tune parameters to match.
Assumptions and deviations
- Body-weight reference (74.9 kg). van Iersel 2018 does not state the body-weight reference for the allometric F1 effect explicitly; this vignette and the model file use 74.9 kg per Fig S4’s ‘median 74.9 kg’ simulation legend, which is also consistent with the ~75 kg mean across the six contributing studies (Table 1).
-
Covariate-equation form ((1 + theta * cov)). The
NONMEM .lst file was not available. The four binary-covariate effects
(
Dosing regimen on CL,Tablet formulation A/B on F1,Food intake on ka,AML/MDS on F1) are encoded as multiplicative (1 + theta * cov) shifts on the typical-value parameter; body weight on F1 is encoded as an allometric-style power exponent on(WT / 74.9). These forms are the convention used here and best match the magnitudes reported in Table 2. - IOV omitted. van Iersel 2018 Table 2 reports interoccasion variability on ka (71.1% CV), D1 (48.6% CV), and F1 (21.4% CV). IOV is NOT encoded in this registry model because the source paper does not define an operational occasion column for the simulation use case; the nlmixr2lib convention (Andrews 2017 / Brooks 2021 precedent) is to omit IOV when no occasion mapping is defined. Downstream users wanting to simulate with IOV should extend the model file with an OCC-aware eta layer using the documented IOV magnitudes.
- Outliers re-introduced. Five samples with CWRES > 6 were treated as outliers during base-model development but reintroduced in the final model used here (van Iersel 2018 Table 2 ‘final model with outliers’ column).
-
Residual-error encoding (lnorm). The paper used
NONMEM’s log-transformed both-sides approach with an additive error on
log-transformed concentration (SD 0.42 in phase 1, SD 0.322 in phase 3).
This is encoded as
Cc ~ lnorm(expSd)withexpSdswitched betweenexpSd_p1andexpSd_p3via theSTUDY_POSA_PHASE3indicator (per the verification-checklist rule ‘NONMEM additive on log-scale = lnorm in nlmixr2 with the same SD’). -
Healthy / HSCT pooling in the AML/MDS effect. The
final model retained AML/MDS as a single indicator; the reference
category therefore pools healthy volunteers and HSCT recipients. The
vignette’s HSCT cohort sets
DIS_MDS_AML = 0to represent the HSCT subgroup of that pooled reference. - Race covariate dropped. The forward-inclusion procedure identified race on CL as a statistically significant covariate but the backward-exclusion procedure dropped it (van Iersel 2018 Results ‘Model development’); race is therefore not in this registry model.
- Original-data unavailable. Patient-level concentrations from the six studies are not publicly available; the figures here use simulated cohorts constructed to match the published demographic ranges.