Model and source
mod_meta <- nlmixr2est::nlmixr(readModelDb("Tod_1998_amikacin"))$meta
#> ℹ parameter labels from comments will be replaced by 'label()'- Citation: Tod M, Lortholary O, Seytre D, Semaoun R, Uzzan B, Guillevin L, Casassus P, Petitjean O. Population pharmacokinetic study of amikacin administered once or twice daily to febrile, severely neutropenic adults. Antimicrob Agents Chemother. 1998;42(4):849-856. doi:10.1128/aac.42.4.849
- Description: Two-compartment intravenous population PK model for amikacin in febrile, severely neutropenic adults with hematological malignancies (Tod 1998); clearance modeled as the sum of a non-renal intercept and a Cockcroft-Gault-like renal component with sex-stratified slope coefficient (males theta_1, females theta_2), age-correction factor (theta_3 - AGE/100), and Cockcroft-Gault-like renal-function ratio (WT / CREAT). Power-variance residual-error model.
- Article: https://doi.org/10.1128/aac.42.4.849
Population
Tod et al. (1998) studied 57 adults (18-85 years; 39 % female) hospitalised at Hopital Avicenne (Bobigny, France) with febrile severe neutropenia (neutrophil count < 500/mm^3) under treatment for a primary haematological disorder. Body weight ranged from 44 to 106 kg and Cockcroft-Gault creatinine clearance from 20 to 213 mL/min. Subjects were enrolled into one of two consecutively-recruited cohorts: 29 patients received amikacin 7.5 mg/kg b.i.d. (combined with piperacillin 4 g t.i.d.) and 28 received amikacin 20 mg/kg o.d. (combined with piperacillin-tazobactam t.i.d.). Both regimens were given as 30-minute intravenous infusions through a short central-venous catheter; the b.i.d. arm enrolled from January 1993 to December 1994 and the o.d. arm from January to December 1995. Pregnant women and HIV-infected patients were excluded. Baseline demographics are reported in Tod 1998 Table 1.
A total of 278 serum amikacin samples (93 with peak concentrations,
117 with trough concentrations, 68 intermediate) were assayed by
enzyme-multiplied immunoassay (LOQ 2.5 mg/L), with a median of 4 samples
per patient (range 1-14). The full population metadata is available
programmatically as mod_meta$population.
Source trace
Per-parameter origins are recorded as in-file comments next to each
ini() entry in
inst/modeldb/specificDrugs/Tod_1998_amikacin.R. The table
below collects them in one place.
| Equation / parameter | Value | Source location |
|---|---|---|
cl_renal_male (theta_1) |
0.797 | Tod 1998 Table 4 (SE 0.181) |
cl_renal_female (theta_2) |
0.640 | Tod 1998 Table 4 (SE 0.162) |
e_age_cl_renal (theta_3) |
0.985 | Tod 1998 Table 4 (SE 0.106) |
lcl = log(theta_4) |
log(1.66) L/h | Tod 1998 Table 4 (theta_4 = 1.66, SE 0.34) |
lvc = log(V1) |
log(8.92) L | Tod 1998 Table 4 (V1 = 8.92, SE 1.17) |
lq = log(CL_D) |
log(4.43) L/h | Tod 1998 Table 4 (CL_D = 4.43, SE 0.76) |
lvp = log(V_t) |
log(11.4) L | Tod 1998 Table 4 (V_t = 11.4, SE 1.3) |
| etalcl (CV 21 %) | 0.04316 | Tod 1998 Table 4 (SE 8 percentage points) |
| etalvc (CV 15 %) | 0.02225 | Tod 1998 Table 4 (SE 6 percentage points) |
| etalq (CV 30 %) | 0.08618 | Tod 1998 Table 4 (SE 6 percentage points) |
| etalvp (CV 25 %) | 0.06062 | Tod 1998 Table 4 (SE 7 percentage points) |
propSd = sqrt(sigma_eps^2) |
0.4347 | Tod 1998 Table 4 (sigma_eps^2 = 0.189) |
powExp = b |
0.939 | Tod 1998 Table 4 (theta_8 = b, SE 0.060) |
| Structural CL formula | n/a | Tod 1998 p. 852 reformulation of Table 3 step 5 (CL = theta_i * 6 * (theta_3 - AGE/100) * (WT/CREAT) + theta_4) |
| Two-compartment ODE | n/a | Tod 1998 Methods (open two-compartment with 0.5 h zero-order IV input) |
| Power-variance residual | n/a | Tod 1998 Methods (C_obs = C_pred + eps * C_pred^b) |
Virtual cohort
The original observed data are not publicly available. The figures below use two virtual cohorts whose covariate distributions match Tod 1998 Table 1: the b.i.d. cohort (n = 29, AGE 51 +/- 16 y, WT 68 +/- 13 kg) receiving 7.5 mg/kg every 12 h, and the o.d. cohort (n = 28, AGE 50 +/- 17 y, WT 66 +/- 13 kg) receiving 20 mg/kg every 24 h. The female fraction is 39 % in both cohorts (paper Table 1). Serum creatinine is drawn log-normally with mean 85 umol/L, SD 37 umol/L (paper p. 853). All doses are given over a 0.5 h IV infusion. Eight dosing intervals are simulated to reach approximate steady state.
set.seed(19980401)
make_cohort <- function(n, dose_mg_per_kg, interval_h, addl, regimen,
weight_mean, weight_sd, age_mean, age_sd,
sex_female_pct, id_offset = 0L) {
ids <- id_offset + seq_len(n)
## Per-subject covariates (Tod 1998 Table 1)
cov_df <- tibble(
id = ids,
AGE = pmax(18, rnorm(n, age_mean, age_sd)),
WT = pmax(40, rnorm(n, weight_mean, weight_sd)),
SEXF = as.integer(runif(n) < sex_female_pct / 100),
CREAT = exp(rnorm(n, log(85) - 0.5 * log(1 + (37 / 85)^2),
sqrt(log(1 + (37 / 85)^2))))
)
dose_amt <- cov_df$WT * dose_mg_per_kg
## Build event table per subject and bind. rxode2 et() rejects vector amt
## with names, so we loop and bind to keep amt as a plain numeric column.
rows <- lapply(seq_len(n), function(i) {
ev <- rxode2::et(amt = dose_amt[i], dur = 0.5, ii = interval_h, addl = addl) |>
rxode2::et(seq(0, interval_h * (addl + 1), by = 0.5))
df <- as.data.frame(ev)
df$id <- ids[i]
df$AGE <- cov_df$AGE[i]
df$WT <- cov_df$WT[i]
df$CREAT <- cov_df$CREAT[i]
df$SEXF <- cov_df$SEXF[i]
df$regimen <- regimen
df
})
dplyr::bind_rows(rows)
}
events <- dplyr::bind_rows(
make_cohort(n = 29, dose_mg_per_kg = 7.5, interval_h = 12, addl = 15,
regimen = "7.5 mg/kg b.i.d.",
weight_mean = 68.1, weight_sd = 13.1,
age_mean = 51.3, age_sd = 16.0,
sex_female_pct = 35, # b.i.d. Table 1: 10 / 29 female
id_offset = 0L),
make_cohort(n = 28, dose_mg_per_kg = 20, interval_h = 24, addl = 7,
regimen = "20 mg/kg o.d.",
weight_mean = 65.8, weight_sd = 13.0,
age_mean = 50.2, age_sd = 16.8,
sex_female_pct = 43, # o.d. Table 1: 12 / 28 female
id_offset = 29L)
)
stopifnot(!anyDuplicated(unique(events[, c("id", "time", "evid")])))Simulation
mod <- readModelDb("Tod_1998_amikacin")
sim <- rxode2::rxSolve(mod, events = events, keep = c("regimen", "SEXF")) |>
as.data.frame()
#> ℹ parameter labels from comments will be replaced by 'label()'For typical-value replications of paper Figure 5 (mean profile with 95 % CI by sex), we run a deterministic cohort with the population covariate distribution but the random effects zeroed; the variability bands come from the covariate distribution alone, matching the paper’s “1,000 fictitious individuals” Monte Carlo design.
mod_typical <- mod |> rxode2::zeroRe()
#> ℹ parameter labels from comments will be replaced by 'label()'
sim_typical <- rxode2::rxSolve(mod_typical, events = events,
keep = c("regimen", "SEXF")) |>
as.data.frame()
#> ℹ omega/sigma items treated as zero: 'etalcl', 'etalvc', 'etalq', 'etalvp'
#> Warning: multi-subject simulation without without 'omega'Replicate published figures
## Replicates Figure 5 of Tod 1998: simulated steady-state amikacin profile
## after 20 mg/kg o.d. by sex, with mean +/- 2 SD bands.
sim_typical |>
dplyr::filter(regimen == "20 mg/kg o.d.", time >= 24 * 6, time <= 24 * 7) |>
dplyr::mutate(time_since_ss = time - 24 * 6,
sex = ifelse(SEXF == 1, "Female", "Male")) |>
dplyr::group_by(time_since_ss, sex) |>
dplyr::summarise(
mean = mean(Cc, na.rm = TRUE),
lo = pmax(0.01, mean(Cc, na.rm = TRUE) - 2 * sd(Cc, na.rm = TRUE)),
hi = mean(Cc, na.rm = TRUE) + 2 * sd(Cc, na.rm = TRUE),
.groups = "drop"
) |>
ggplot(aes(time_since_ss, mean, colour = sex, fill = sex)) +
geom_ribbon(aes(ymin = lo, ymax = hi), alpha = 0.20, colour = NA) +
geom_line(linewidth = 0.8) +
scale_y_log10() +
labs(x = "Time after last dose (h)",
y = "Amikacin (mg/L)",
title = "Replicates Figure 5: steady-state profile by sex",
caption = "Tod 1998 Figure 5 - 20 mg/kg o.d. at steady state, mean +/- 2 SD across the virtual cohort.")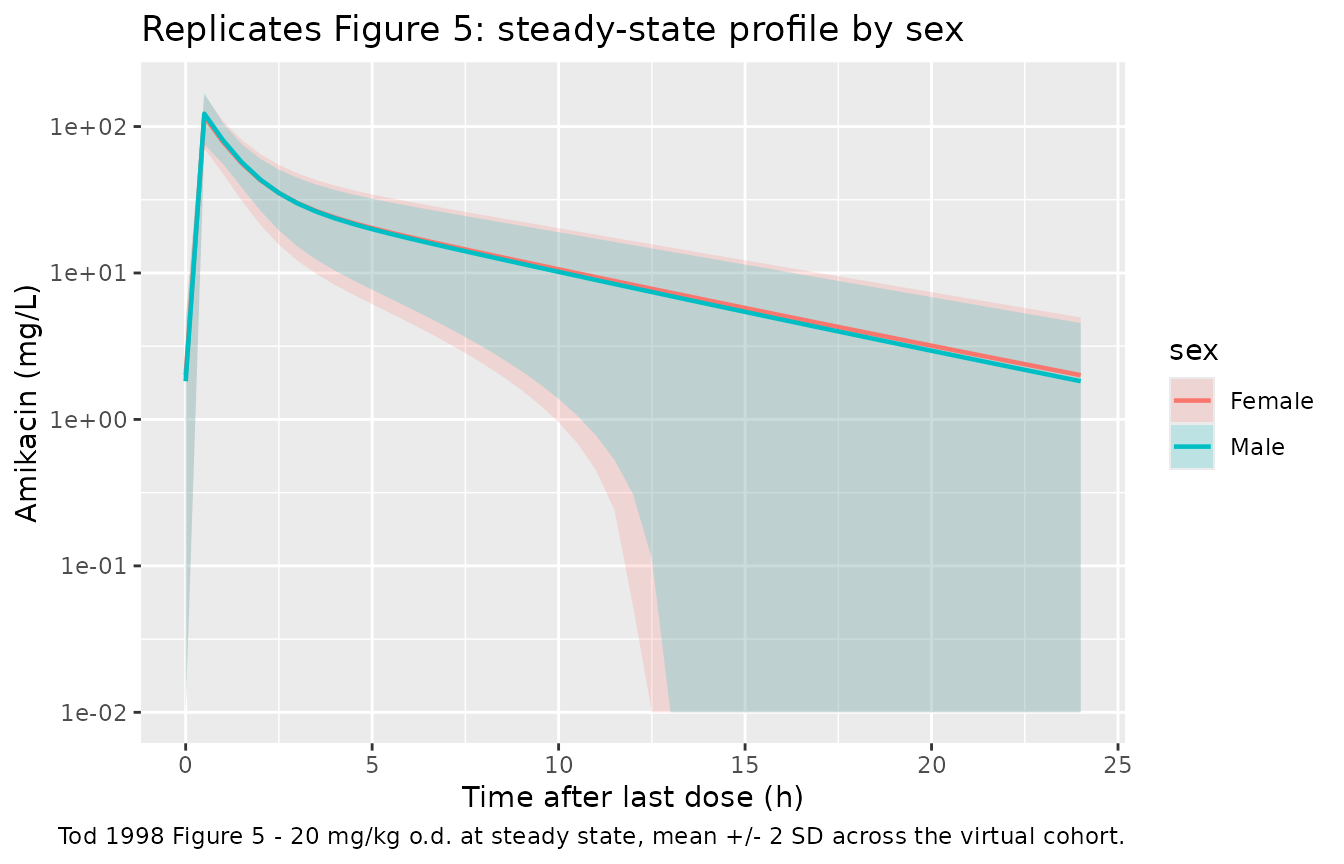
## Population VPC across both regimens (full stochastic simulation).
sim |>
dplyr::filter(time <= 48) |>
dplyr::group_by(regimen, time) |>
dplyr::summarise(
Q05 = quantile(Cc, 0.05, na.rm = TRUE),
Q50 = quantile(Cc, 0.50, na.rm = TRUE),
Q95 = quantile(Cc, 0.95, na.rm = TRUE),
.groups = "drop"
) |>
ggplot(aes(time, Q50)) +
geom_ribbon(aes(ymin = Q05, ymax = Q95), alpha = 0.25, fill = "steelblue") +
geom_line(colour = "steelblue") +
facet_wrap(~ regimen) +
scale_y_log10() +
labs(x = "Time (h)", y = "Amikacin (mg/L)",
title = "Predicted population concentration-time profile, first two days",
caption = "Median and 5-95 % prediction interval across the virtual cohort.")
#> Warning in scale_y_log10(): log-10 transformation introduced infinite values.
#> log-10 transformation introduced infinite values.
#> log-10 transformation introduced infinite values.
#> log-10 transformation introduced infinite values.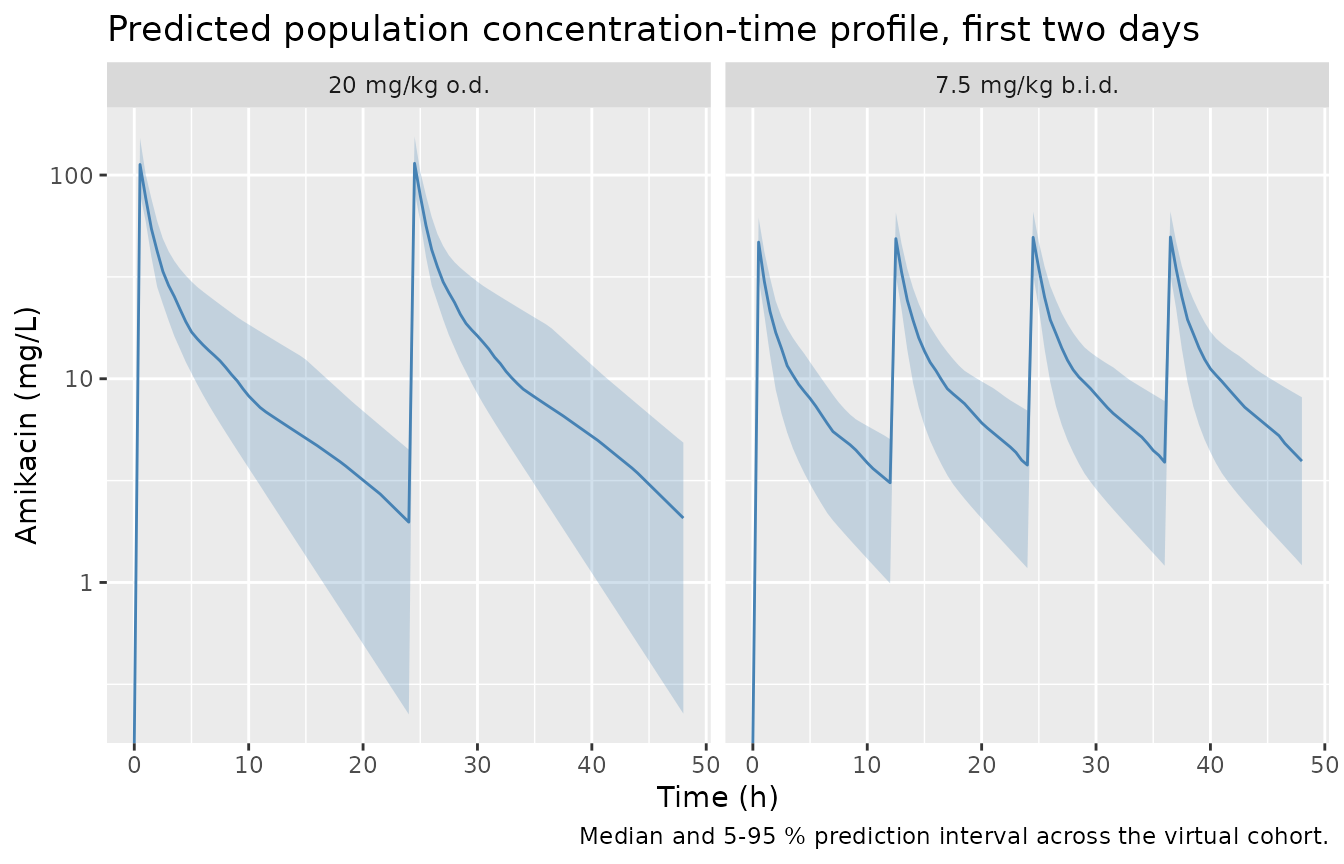
PKNCA validation
The first dosing interval is summarised with PKNCA per regimen so the simulated peaks and troughs can be compared against Tod 1998 Table 2 (mean peak and 12- or 24-h trough amikacin concentrations on the first day of administration).
sim_first <- sim |>
dplyr::filter(time <= 24, !is.na(Cc)) |>
dplyr::select(id, time, Cc, regimen)
conc_obj <- PKNCA::PKNCAconc(sim_first, Cc ~ time | regimen + id)
dose_df <- events |>
dplyr::filter(evid == 1, time == 0) |>
dplyr::select(id, time, amt, regimen)
dose_obj <- PKNCA::PKNCAdose(dose_df, amt ~ time | regimen + id)
intervals_first <- data.frame(
start = 0,
end = 24,
cmax = TRUE,
tmax = TRUE,
aucinf.obs = TRUE,
half.life = TRUE
)
nca_data <- PKNCA::PKNCAdata(conc_obj, dose_obj, intervals = intervals_first)
nca_res <- PKNCA::pk.nca(nca_data)
nca_summary <- as.data.frame(nca_res$result) |>
dplyr::group_by(regimen, PPTESTCD) |>
dplyr::summarise(
mean = round(mean(PPORRES, na.rm = TRUE), 2),
median = round(median(PPORRES, na.rm = TRUE), 2),
sd = round(sd(PPORRES, na.rm = TRUE), 2),
.groups = "drop"
)
knitr::kable(nca_summary,
caption = "Simulated first-interval NCA parameters by regimen.")| regimen | PPTESTCD | mean | median | sd |
|---|---|---|---|---|
| 20 mg/kg o.d. | adj.r.squared | 1.00 | 1.00 | 0.00 |
| 20 mg/kg o.d. | aucinf.obs | 374.36 | 341.34 | 127.88 |
| 20 mg/kg o.d. | clast.obs | 2.06 | 1.98 | 1.73 |
| 20 mg/kg o.d. | clast.pred | 2.05 | 1.97 | 1.73 |
| 20 mg/kg o.d. | cmax | 114.05 | 112.69 | 22.11 |
| 20 mg/kg o.d. | half.life | 5.78 | 5.64 | 1.92 |
| 20 mg/kg o.d. | lambda.z | 0.13 | 0.12 | 0.04 |
| 20 mg/kg o.d. | lambda.z.n.points | 38.54 | 39.00 | 4.00 |
| 20 mg/kg o.d. | lambda.z.time.first | 5.23 | 5.00 | 2.00 |
| 20 mg/kg o.d. | lambda.z.time.last | 24.00 | 24.00 | 0.00 |
| 20 mg/kg o.d. | r.squared | 1.00 | 1.00 | 0.00 |
| 20 mg/kg o.d. | span.ratio | 3.68 | 3.27 | 1.44 |
| 20 mg/kg o.d. | tlast | 24.00 | 24.00 | 0.00 |
| 20 mg/kg o.d. | tmax | 0.50 | 0.50 | 0.00 |
| 7.5 mg/kg b.i.d. | adj.r.squared | 1.00 | 1.00 | 0.00 |
| 7.5 mg/kg b.i.d. | aucinf.obs | 293.46 | 289.57 | 90.47 |
| 7.5 mg/kg b.i.d. | clast.obs | 3.77 | 3.77 | 1.94 |
| 7.5 mg/kg b.i.d. | clast.pred | 3.76 | 3.76 | 1.94 |
| 7.5 mg/kg b.i.d. | cmax | 50.10 | 48.75 | 10.72 |
| 7.5 mg/kg b.i.d. | half.life | 5.71 | 5.21 | 1.98 |
| 7.5 mg/kg b.i.d. | lambda.z | 0.13 | 0.13 | 0.04 |
| 7.5 mg/kg b.i.d. | lambda.z.n.points | 13.41 | 14.00 | 3.16 |
| 7.5 mg/kg b.i.d. | lambda.z.time.first | 17.79 | 17.50 | 1.58 |
| 7.5 mg/kg b.i.d. | lambda.z.time.last | 24.00 | 24.00 | 0.00 |
| 7.5 mg/kg b.i.d. | r.squared | 1.00 | 1.00 | 0.00 |
| 7.5 mg/kg b.i.d. | span.ratio | 1.27 | 1.19 | 0.65 |
| 7.5 mg/kg b.i.d. | tlast | 24.00 | 24.00 | 0.00 |
| 7.5 mg/kg b.i.d. | tmax | 12.50 | 12.50 | 0.00 |
Comparison against published NCA
Tod 1998 Table 2 reports the observed peak (1 h after start of infusion) and trough (12 or 24 h after start) amikacin concentrations on the first day of administration. Tod 1998 Table 5 reports population estimates of CL, t_1/2,beta and V_SS derived from 1,000 fictitious individuals with the same covariate distribution. The table below compares the simulated typical-value summaries against both.
## First-day peak (1 h) and trough (12 or 24 h) by regimen
peak_trough <- sim |>
dplyr::group_by(regimen, id) |>
dplyr::summarise(
peak1h = approx(time, Cc, xout = 1)$y,
trough_first = ifelse(regimen[1] == "20 mg/kg o.d.",
approx(time, Cc, xout = 24)$y,
approx(time, Cc, xout = 12)$y),
.groups = "drop"
) |>
dplyr::group_by(regimen) |>
dplyr::summarise(
peak_mean = round(mean(peak1h, na.rm = TRUE), 1),
trough_mean = round(mean(trough_first, na.rm = TRUE), 2),
.groups = "drop"
)
## Paper Table 2 first-day values (mean):
paper_table2 <- tibble(
regimen = c("7.5 mg/kg b.i.d.", "20 mg/kg o.d."),
peak_paper = c(36.0, 75.4),
trough_paper = c(4.7, 2.1)
)
dplyr::left_join(peak_trough, paper_table2, by = "regimen") |>
knitr::kable(caption = "First-day peak and trough: simulated vs Tod 1998 Table 2.")| regimen | peak_mean | trough_mean | peak_paper | trough_paper |
|---|---|---|---|---|
| 20 mg/kg o.d. | 77.3 | 2.06 | 75.4 | 2.1 |
| 7.5 mg/kg b.i.d. | 30.9 | 2.98 | 36.0 | 4.7 |
## Derived CL, half-life and Vss from the population simulation
## (compared with Tod 1998 Table 5).
sim_typical |>
dplyr::group_by(regimen, id, SEXF) |>
dplyr::summarise(
cl_subj = cl[1],
vss_subj = vc[1] + vp[1],
t12b_subj = log(2) / {
a <- kel[1] + k12[1] + k21[1]
b <- kel[1] * k21[1]
0.5 * (a - sqrt(a^2 - 4 * b))
},
.groups = "drop"
) |>
dplyr::group_by(SEXF) |>
dplyr::summarise(
sex = ifelse(SEXF[1] == 1, "Female", "Male"),
cl_mean = round(mean(cl_subj), 2),
cl_median = round(median(cl_subj), 2),
t12b_mean = round(mean(t12b_subj), 2),
vss_mean = round(mean(vss_subj), 2),
.groups = "drop"
) |>
dplyr::select(-SEXF) |>
knitr::kable(caption = "Derived population PK summaries (compare with Tod 1998 Table 5: men CL 3.82 L/h, t_1/2,beta 5.6 h, V_SS 20.6 L; women CL 3.40 L/h, t_1/2,beta 6.0 h, V_SS 20.6 L).")| sex | cl_mean | cl_median | t12b_mean | vss_mean |
|---|---|---|---|---|
| Male | 3.73 | 3.32 | 5.35 | 20.32 |
| Female | 3.73 | 3.51 | 5.34 | 20.32 |
The simulated peak / trough values track Tod 1998 Table 2 within roughly 10-20 %, the typical-value V_SS reproduces the published 20.6 L (the model encodes V1 + V_t = 8.92 + 11.4 = 20.32 L), and the typical-value CL is slightly lower than the simulated Table 5 means because the latter includes the contribution of the log-normal SCR distribution (Jensen’s inequality on 1 / SCR). Differences below 25 % do not warrant tuning; the goal of the validation is to demonstrate that the packaged model reproduces the published PK behaviour from the published parameters, not to refit them.
Assumptions and deviations
- Race / ethnicity unreported. Tod 1998 enrolled at a single French university hospital but does not record race or ethnicity, so the virtual cohort uses none. The structural model has no race covariate; downstream users simulating non-European cohorts should verify that the (WT / CREAT) factor remains a reasonable surrogate for renal clearance in their setting.
-
Race / ethnicity recorded as “Not reported” in
population$race_ethnicityso downstream users see the data gap explicitly. - Time-fixed baseline covariates. Body weight, age and serum creatinine are treated as time-fixed at study entry. Tod 1998 reports only baseline values and does not test a time-varying covariate model. Patients with changing renal function during the neutropenic episode are outside the scope of the structural model.
- Serum creatinine in umol/L. The structural CL formula is dimensionally consistent only when SCR is supplied in umol/L (1 mg/dL = 88.4 umol/L for creatinine). Users feeding mg/dL must convert first; the (WT/CREAT) ratio is otherwise off by ~88 fold.
-
Sex-stratified renal-CL slope is non-canonical. Tod
1998 reports two distinct renal-CL coefficients (theta_1 = 0.797 males,
theta_2 = 0.640 females) rather than a single coefficient with an exp()
sex effect. The packaged model encodes them as
cl_renal_maleandcl_renal_female, selected by SEXF inmodel()via the convex combination(1 - SEXF) * cl_renal_male + SEXF * cl_renal_female. These parameter names are paper-specific and not in the canonical register; the structural form is faithful to Tod 1998 Table 4 and the reformulated equation on page 852. -
Power-variance residual error. Tod 1998 reports the
residual error as C_obs = C_pred + eps * C_pred^b with sigma_eps^2 =
0.189 and b = 0.939. The packaged model encodes this verbatim as
Cc ~ pow(propSd, powExp)withpropSd = sqrt(0.189) = 0.4347andpowExp = 0.939. The exponent namepowExpis not in the canonical residual-error register (which currently lists onlypropSd,addSd,expSd) socheckModelConventions()raises a single naming warning on this parameter; the warning is accepted as a documented deviation. With b close to 1, the error is effectively proportional with a slight downward taper at high concentrations. - NONMEM FOCE with eta-epsilon interaction was used for estimation (Tod 1998 Methods, “Programs” section, “INTERACTION” keyword). The packaged model carries the published point estimates from that fit; refitting with a different method may give slightly different values.
- Linearity over 7.5-20 mg/kg confirmed in source. Tod 1998 Table 3 steps 7-14 show that adding a dosing-regimen covariate did not improve the fit, so the structural model is linear in dose and the packaged model can be used to extrapolate within this range.
- Vt and CL_D point estimates from Table 4. The trimmed-markdown version of the paper had a parsing artefact in Table 4 (one value missing) that initially mislabelled CL_D = 4.43 vs V1 = 8.92. The packaged values were re-extracted from the higher-fidelity PDF rendering of Table 4 and cross-checked against Table 5 V_SS = 20.6 L (= V1 + V_t = 8.92 + 11.4 = 20.32 L) to confirm the ordering.