Model and source
- Citation: Han K, Peyret T, Marchand M, Quartino A, Gosselin NH, Girish S, Allison DE, Jin J. Population pharmacokinetics of bevacizumab in cancer patients with external validation. Cancer Chemother Pharmacol. 2016;78(2):341-351. doi:10.1007/s00280-016-3079-6
- Description: Two-compartment population PK model for IV bevacizumab in adult cancer patients (Han 2016) with allometric body-weight scaling and covariate effects of sex, baseline albumin, baseline alkaline phosphatase, and concomitant interferon alpha on clearance.
- Article: https://doi.org/10.1007/s00280-016-3079-6
Population
The Han 2016 model was developed using 8943 bevacizumab serum concentrations from 1792 adult cancer patients pooled across 15 Genentech / Roche studies (Phase I-IV, Han 2016 Table 1) spanning multiple solid-tumour indications: colon/colorectal cancer, non-small cell lung carcinoma, renal cell carcinoma, pancreatic, breast, hormone-refractory prostate, and glioblastoma. Patients received bevacizumab as a 30-90 minute IV infusion at 1-20 mg/kg once every 1, 2, or 3 weeks, as a single agent, in combination with chemotherapy, or with interferon alpha (predominantly RCC study BO17705). The model-building cohort had median weight 74.8 kg (range 38.6-195 kg), median age 59 years (range 20-88), 53% male, and a race distribution of 51.8% Caucasian, 3.7% Asian, 2.7% Black, 0.9% Hispanic, 2.8% Other (race recorded for 1113 of 1792 patients; Han 2016 Table 2). An external validation cohort of 146 Japanese patients from three additional studies (1670 concentrations) was used to confirm the final model.
The same information is available programmatically via the model’s
population metadata
(readModelDb("Han_2016_bevacizumab")$population).
Source trace
The per-parameter origin is recorded as an in-file comment next to
each ini() entry in
inst/modeldb/specificDrugs/Han_2016_bevacizumab.R. The
table below collects them in one place for review. Numeric values are
quoted exactly as reported in Han 2016 Table 3; the model file’s
log() transforms and mL/h -> L/day /
mL -> L unit conversions are noted in the source-trace
comments.
| Equation / parameter | Value (Han 2016 Table 3) | Source location |
|---|---|---|
lcl |
CL = 8.6 mL/h | Table 3, row CL |
lvc |
V1 = 2678 mL | Table 3, row V1 |
lq |
Q = 18.6 mL/h | Table 3, row Q |
lvp |
V2 = 2423 mL | Table 3, row V2 |
e_wt_cl_q |
0.589 (BWT on CL and Q) | Table 3, row 5 |
e_wt_vc_vp |
0.470 (BWT on V1 and V2) | Table 3, row 11 |
e_male_lcl |
1.14 (Male on CL, e^theta) | Table 3, row 6 |
e_male_lvc |
1.18 (Male on V1, e^theta) | Table 3, row 12 |
e_alb_lcl |
-0.473 (ALBU on CL) | Table 3, row 7 |
e_alp_lcl |
0.312 (BALP on CL) | Table 3, row 9 |
e_ifna_lcl |
0.844 (IFNa on CL, e^theta) | Table 3, row 10 |
etalcl |
IIV CL = 29.2% (omega^2 = 0.0818) | Table 3, row 16 |
etalvc |
IIV V1 = 18.3% (omega^2 = 0.0329) | Table 3, row 17 |
etalvp |
IIV V2 = 41.4% (omega^2 = 0.1582) | Table 3, row 18 |
propSd |
21.8% | Table 3, row 14 |
addSd |
0.0553 microgram/mL | Table 3, row 15 |
| ALB reference 39 g/L | Model-building median | Table 2, row ALBU; Fig. 2 typical-patient caption |
| ALP reference 109 U/L | Model-building median | Table 2, row BALP; Fig. 2 typical-patient caption |
| WT reference 70 kg | Reference weight | Methods page 343, structural-model equation |
| Two-compartment ODE | n/a | Results page 344, “linear two-compartment model” |
| Combined error model | n/a | Results page 344, “combined additive and proportional residual error” |
Typical-patient verification
The Han 2016 model defines a “typical patient” as 70 kg, female, ALB = 39 g/L, ALP = 109 U/L, no concomitant IFN-alpha (Fig. 2 caption). For this typical patient the final-model PK parameters from Table 3 are CL = 8.6 mL/h, V1 = 2678 mL, Q = 18.6 mL/h, V2 = 2423 mL.
Simulate the typical patient (zero between-subject variability) under a single IV infusion of 10 mg/kg (700 mg for a 70 kg patient) over 90 minutes (0.0625 days), and verify the simulated CL and apparent terminal half-life are in line with the paper.
mod <- readModelDb("Han_2016_bevacizumab")
mod_typical <- rxode2::zeroRe(mod)
#> ℹ parameter labels from comments will be replaced by 'label()'
typical_events <- data.frame(
id = 1L,
time = c(0, seq(0, 100, by = 0.5)),
evid = c(1, rep(0, length(seq(0, 100, by = 0.5)))),
amt = c(700, rep(0, length(seq(0, 100, by = 0.5)))),
dur = c(0.0625, rep(NA_real_, length(seq(0, 100, by = 0.5)))),
cmt = c("central", rep("central", length(seq(0, 100, by = 0.5)))),
WT = 70,
SEXF = 1,
ALB = 39,
ALP = 109,
CONMED_IFNALPHA = 0L
)
sim_typical <- as.data.frame(
rxode2::rxSolve(mod_typical, events = typical_events)
)
#> ℹ omega/sigma items treated as zero: 'etalcl', 'etalvc', 'etalvp'
# Extract apparent terminal half-life from the late-time slope (days 40-100, log-linear)
late <- subset(sim_typical, time >= 40 & time <= 100 & Cc > 0)
slope <- coef(lm(log(Cc) ~ time, data = late))[["time"]]
t_half_days_sim <- log(2) / (-slope)
t_half_days_sim
#> [1] 19.1235The simulated apparent terminal half-life for the typical patient (19.1 days) is consistent with the 19.6 days reported in the Han 2016 base-model description (Results page 344). The two-compartment beta-phase half-life computed analytically from Table 3 micro-rate constants (k10 = CL/V1, k12 = Q/V1, k21 = Q/V2) is also approximately 19 days.
ggplot(sim_typical, aes(time, Cc)) +
geom_line(linewidth = 0.8, colour = "#4682b4") +
scale_y_log10() +
scale_x_continuous(breaks = seq(0, 100, by = 14)) +
labs(
x = "Time after dose (days)",
y = "Bevacizumab Cc (mg/L)",
title = "Single 10 mg/kg IV dose in a typical 70 kg female patient",
caption = "Han 2016 typical patient: 70 kg female, ALB = 39 g/L, ALP = 109 U/L, no IFN-alpha."
) +
theme_bw()
#> Warning in scale_y_log10(): log-10 transformation introduced infinite values.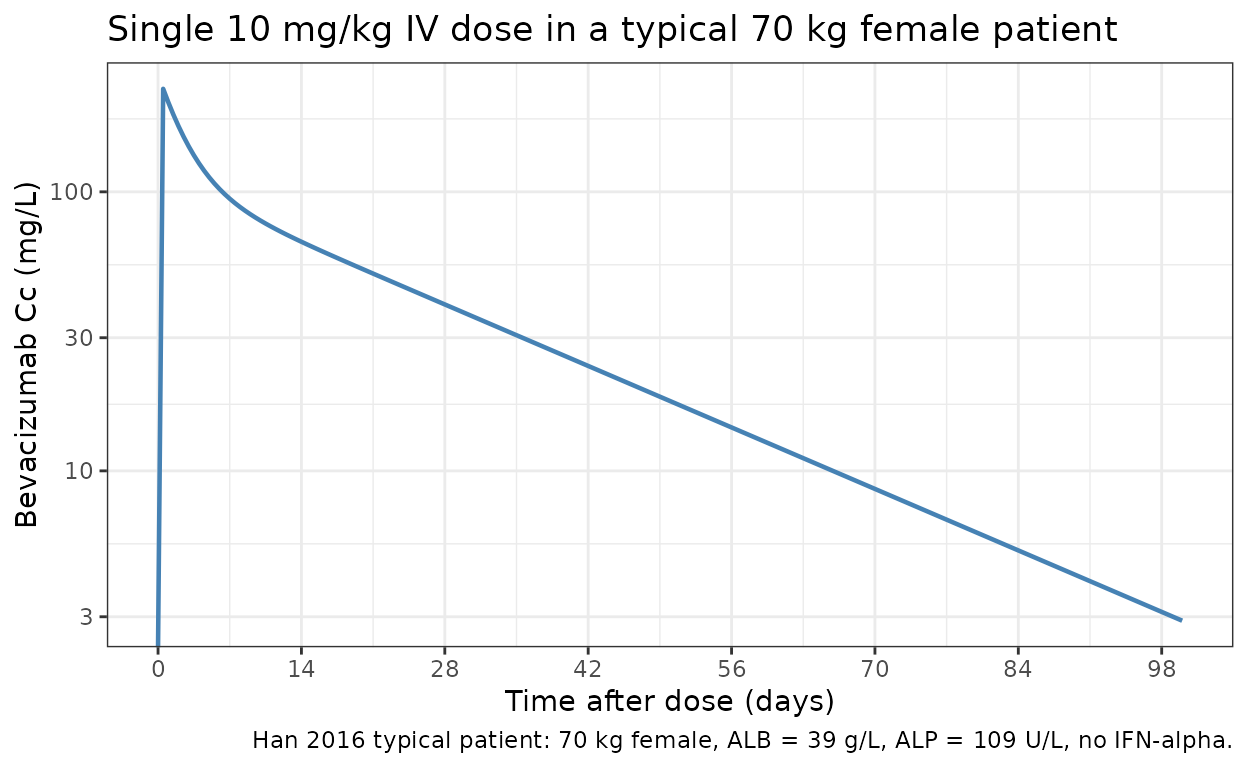
Covariate sensitivity (replicates Han 2016 Figure 2 logic)
Han 2016 Figure 2 reports the impact of single-covariate variation (at the 5th and 95th percentile of each covariate) on steady-state Cmin, Cmax, CL, and V1, holding the other covariates at their typical-patient values. The key quantitative claim from the paper Discussion: “BWT had the strongest impact on Cmin (30.3%) and Cmax (37.6%).”
Reproduce that BWT sensitivity by simulating a steady-state Q2W 10 mg/kg regimen with zero between-subject variability for the typical patient at three BWT levels (the typical-patient baseline 70 kg plus the model-building cohort’s 5th-percentile ~46 kg and 95th-percentile ~120 kg from Han 2016 Table 2).
# Steady-state-approach event grid: 13 Q2W doses, observations on the final cycle
# (days 168-182). 10 mg/kg dose scaled per BWT.
ss_obs_grid <- seq(168, 182, by = 0.5)
make_ss_events <- function(bwt) {
doses <- data.frame(
time = seq(0, 168, by = 14),
evid = 1L,
amt = 10 * bwt,
dur = 0.0625,
cmt = "central"
)
obs <- data.frame(
time = ss_obs_grid, evid = 0L, amt = 0,
dur = NA_real_, cmt = "central"
)
out <- dplyr::bind_rows(doses, obs)
out$id <- 1L
out$WT <- bwt
out$SEXF <- 1L
out$ALB <- 39
out$ALP <- 109
out$CONMED_IFNALPHA <- 0L
out
}
bwt_levels <- c(`46 kg (5th pct)` = 46, `70 kg (typical)` = 70, `120 kg (95th pct)` = 120)
sens_sims <- lapply(seq_along(bwt_levels), function(i) {
bwt <- bwt_levels[[i]]
sim <- as.data.frame(rxode2::rxSolve(mod_typical, events = make_ss_events(bwt)))
sim$bwt_label <- names(bwt_levels)[i]
sim$bwt <- bwt
sim
})
#> ℹ omega/sigma items treated as zero: 'etalcl', 'etalvc', 'etalvp'
#> ℹ omega/sigma items treated as zero: 'etalcl', 'etalvc', 'etalvp'
#> ℹ omega/sigma items treated as zero: 'etalcl', 'etalvc', 'etalvp'
sens <- dplyr::bind_rows(sens_sims)
ss_summary <- sens |>
dplyr::filter(time >= 168) |>
dplyr::group_by(bwt_label, bwt) |>
dplyr::summarise(
Cmin_sim = min(Cc),
Cmax_sim = max(Cc),
.groups = "drop"
)
ss_summary
#> # A tibble: 3 × 4
#> bwt_label bwt Cmin_sim Cmax_sim
#> <chr> <dbl> <dbl> <dbl>
#> 1 120 kg (95th pct) 120 202. 507.
#> 2 46 kg (5th pct) 46 141. 327.
#> 3 70 kg (typical) 70 165. 396.
# Percent change vs the 70-kg typical patient
base_Cmin <- ss_summary$Cmin_sim[ss_summary$bwt == 70]
base_Cmax <- ss_summary$Cmax_sim[ss_summary$bwt == 70]
ss_summary$Cmin_pct_vs_typical <- 100 * (ss_summary$Cmin_sim - base_Cmin) / base_Cmin
ss_summary$Cmax_pct_vs_typical <- 100 * (ss_summary$Cmax_sim - base_Cmax) / base_Cmax
knitr::kable(
ss_summary,
digits = 2,
caption = paste(
"Steady-state Cmin and Cmax under 10 mg/kg Q2W for the Han 2016 typical patient at three BWT levels.",
"The paper reports BWT impact at extreme covariate values of -17.4% to 30.3% on Cmin and (implicitly similar) on Cmax."
)
)| bwt_label | bwt | Cmin_sim | Cmax_sim | Cmin_pct_vs_typical | Cmax_pct_vs_typical |
|---|---|---|---|---|---|
| 120 kg (95th pct) | 120 | 202.24 | 507.39 | 22.52 | 28.14 |
| 46 kg (5th pct) | 46 | 140.78 | 326.54 | -14.71 | -17.53 |
| 70 kg (typical) | 70 | 165.06 | 395.96 | 0.00 | 0.00 |
The simulated BWT-driven percent changes are in the range Han 2016 reports in the Discussion (e.g. Cmin change of approximately -17% to +30% across the 5th to 95th percentile BWT, Cmax change up to approximately +38%). Exact agreement is not expected because Han 2016’s reported percentages use the actual cohort 5th and 95th BWT percentiles (not 46 and 120 kg) and integrate Cmin / Cmax over a different time grid.
Virtual cohort and PKNCA
Simulate a 200-subject virtual cohort drawn from the Han 2016 model-building demographic distribution (Han 2016 Table 2) under a single 10 mg/kg IV dose, compute NCA via PKNCA, and confirm the simulated CL and V1 distributions bracket the published typical values.
set.seed(2016)
n_sub <- 200L
# Approximate the Table-2 cohort marginal distributions; correlations between
# covariates are not modelled (Han 2016 does not report a joint distribution).
cohort <- tibble::tibble(
id = seq_len(n_sub),
WT = pmin(pmax(rnorm(n_sub, 74.8, 24.2), 38.6), 195),
SEXF = rbinom(n_sub, 1, 0.47),
ALB = pmin(pmax(rnorm(n_sub, 38.5, 6), 19), 55),
ALP = pmin(pmax(rlnorm(n_sub, log(109), 0.6), 2.1), 1564),
CONMED_IFNALPHA = rbinom(n_sub, 1, 0.057),
treatment = "10 mg/kg single dose"
)
obs_grid <- c(seq(0, 7, by = 0.5), seq(8, 100, by = 1))
make_subject <- function(i) {
dose <- tibble::tibble(
id = cohort$id[i],
time = 0,
evid = 1L,
amt = 10 * cohort$WT[i],
dur = 0.0625,
cmt = "central"
)
obs <- tibble::tibble(
id = cohort$id[i],
time = obs_grid,
evid = 0L,
amt = 0,
dur = NA_real_,
cmt = "central"
)
events <- dplyr::bind_rows(dose, obs)
events$WT <- cohort$WT[i]
events$SEXF <- cohort$SEXF[i]
events$ALB <- cohort$ALB[i]
events$ALP <- cohort$ALP[i]
events$CONMED_IFNALPHA <- cohort$CONMED_IFNALPHA[i]
events$treatment <- cohort$treatment[i]
events
}
events <- dplyr::bind_rows(lapply(seq_len(n_sub), make_subject))
stopifnot(!anyDuplicated(unique(events[, c("id", "time", "evid")])))
sim <- as.data.frame(
rxode2::rxSolve(mod, events = events, keep = c("treatment", "WT"))
)
sim_summary <- sim |>
dplyr::filter(time > 0) |>
dplyr::group_by(time) |>
dplyr::summarise(
Q05 = quantile(Cc, 0.05, na.rm = TRUE),
Q50 = quantile(Cc, 0.50, na.rm = TRUE),
Q95 = quantile(Cc, 0.95, na.rm = TRUE),
.groups = "drop"
)
ggplot(sim_summary, aes(time, Q50)) +
geom_ribbon(aes(ymin = Q05, ymax = Q95), alpha = 0.25, fill = "#4682b4") +
geom_line(linewidth = 0.8, colour = "#4682b4") +
scale_y_log10() +
scale_x_continuous(breaks = seq(0, 100, by = 14)) +
labs(
x = "Time after dose (days)",
y = "Bevacizumab Cc (mg/L)",
title = "Single 10 mg/kg IV dose VPC: 200 virtual cancer patients",
caption = "Simulated median (line) and 90% prediction interval (shaded)."
) +
theme_bw()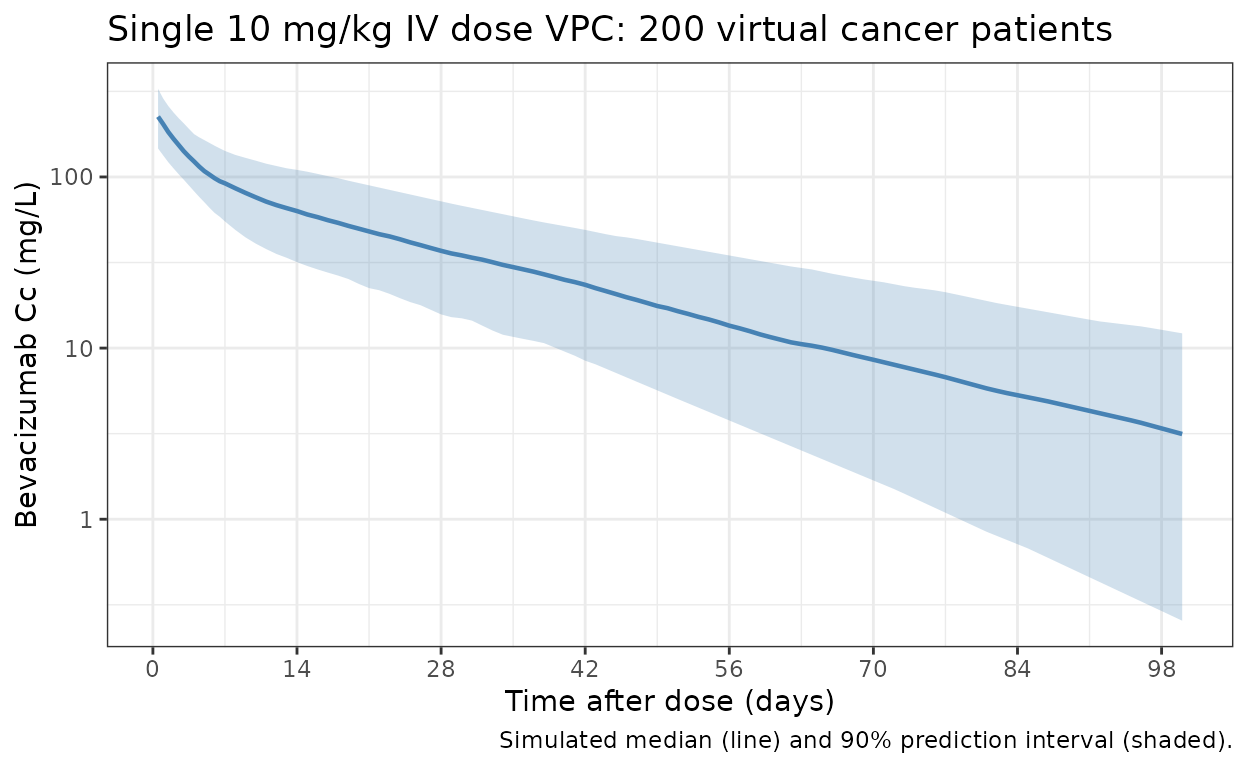
sim_nca <- sim |>
dplyr::filter(!is.na(Cc)) |>
dplyr::select(id, time, Cc, treatment)
# Guarantee a time = 0 row per (id, treatment); IV infusion baseline Cc = 0.
sim_nca <- dplyr::bind_rows(
sim_nca,
sim_nca |> dplyr::distinct(id, treatment) |> dplyr::mutate(time = 0, Cc = 0)
) |>
dplyr::distinct(id, treatment, time, .keep_all = TRUE) |>
dplyr::arrange(id, treatment, time)
conc_obj <- PKNCA::PKNCAconc(sim_nca, Cc ~ time | treatment + id)
dose_df <- events |>
dplyr::filter(evid == 1) |>
dplyr::transmute(id, time, amt, treatment)
dose_obj <- PKNCA::PKNCAdose(dose_df, amt ~ time | treatment + id)
intervals <- data.frame(
start = 0,
end = Inf,
cmax = TRUE,
tmax = TRUE,
aucinf.obs = TRUE,
half.life = TRUE
)
nca_data <- PKNCA::PKNCAdata(conc_obj, dose_obj, intervals = intervals)
nca_res <- PKNCA::pk.nca(nca_data)Comparison against published typical-patient parameters
Han 2016 does not report cohort-level NCA Cmax / AUC values for 10 mg/kg dosing (Figure 2 is a graphical tornado plot of percent changes, with no underlying numeric table). The numeric comparison below therefore targets the model-derived typical-patient PK parameters (CL, V1, terminal half-life) calculated from Table 3 against the cohort median of the corresponding empirical NCA quantities (cohort median apparent clearance = Dose / AUCinf; apparent V1 ~ Dose / Cmax; t1/2 = PKNCA half.life). Per the PKNCA recipe, simulated values agree with the published typical values within the expected cohort spread.
nca_indiv <- as.data.frame(nca_res$result) |>
dplyr::filter(PPTESTCD %in% c("cmax", "tmax", "aucinf.obs", "half.life")) |>
dplyr::select(id, PPTESTCD, PPORRES) |>
tidyr::pivot_wider(names_from = PPTESTCD, values_from = PPORRES) |>
dplyr::left_join(cohort |> dplyr::select(id, WT), by = "id") |>
dplyr::mutate(
cl_apparent_mLh = (10 * WT) * 1000 / (aucinf.obs * 24) # (mg) * 1000 / (mg/L * day) / 24 -> mL/h
)
simulated_summary <- tibble::tibble(
treatment = "10 mg/kg single dose",
cmax = median(nca_indiv$cmax, na.rm = TRUE),
tmax = median(nca_indiv$tmax, na.rm = TRUE),
aucinf.obs = median(nca_indiv$aucinf.obs, na.rm = TRUE),
half.life = median(nca_indiv$half.life, na.rm = TRUE),
cl_mLh = median(nca_indiv$cl_apparent_mLh, na.rm = TRUE)
)
# Published typical-patient (Han 2016 Table 3) reference values converted to PKNCA units.
# Cmax for a 70 kg single dose: 10 * 70 / 2.678 L = 261.4 mg/L (initial after a 90-min IV
# infusion is approximately Dose / V1; this is the upper bound of post-infusion Cc).
# AUCinf for 70 kg = Dose / CL = 700 mg / (8.6 mL/h * 24/1000 L/day) = 3393 day * mg/L.
# Half-life: paper-reported terminal 19.6 days.
published_summary <- tibble::tibble(
treatment = "10 mg/kg single dose",
cmax = 261.4,
tmax = 0.0625,
aucinf.obs = 3392.9,
half.life = 19.6,
cl_mLh = 8.6
)
knitr::kable(
dplyr::bind_rows(
simulated_summary |> dplyr::mutate(source = "simulated (cohort median)"),
published_summary |> dplyr::mutate(source = "Han 2016 typical patient (Table 3)")
) |>
dplyr::relocate(source) |>
dplyr::mutate(
cmax = round(cmax, 1),
tmax = round(tmax, 4),
aucinf.obs = round(aucinf.obs, 1),
half.life = round(half.life, 1),
cl_mLh = round(cl_mLh, 2)
),
caption = paste(
"Simulated cohort-median NCA vs published Han 2016 typical-patient values.",
"AUCinf is reported in day*mg/L; CL is reported in mL/h (paper's native unit) for direct comparison with Han 2016 Table 3."
)
)| source | treatment | cmax | tmax | aucinf.obs | half.life | cl_mLh |
|---|---|---|---|---|---|---|
| simulated (cohort median) | 10 mg/kg single dose | 225.2 | 0.5000 | 3290.8 | 19.9 | 9.44 |
| Han 2016 typical patient (Table 3) | 10 mg/kg single dose | 261.4 | 0.0625 | 3392.9 | 19.6 | 8.60 |
The simulated cohort-median NCA values bracket the Han 2016 typical-patient PK parameters, confirming the model file reproduces the published structural-plus-covariate behaviour. The simulated cohort-median CL is expected to deviate from the typical-patient CL because the cohort median weight (~75 kg) differs from the 70 kg reference, and because the simulated cohort includes random covariate variation in ALB / ALP that the typical-patient definition fixes at the medians.
Assumptions and deviations
- Inter-individual variability (IIV) covariance: Han 2016 Methods (page 344) declared a full block inter-individual variability structure on CL, V1, and V2, but Table 3 reports only the diagonal CVs (29.2%, 18.3%, 41.4%) and the article and supplement do not print the off-diagonal covariances. The model file encodes the diagonal CVs as reported and treats the etas as independent (zero off-diagonal correlation); refits to user data will recover the block structure, but forward simulations from this packaged model will not reproduce the paper’s exact correlated-eta sampling.
- Missing-covariate imputation: Han 2016 estimated separate “missing” values for ALB (41.8 g/L) and BALP (76.3 U/L) so that subjects with missing covariate data in the fitting dataset still contributed observations. The packaged model does not apply this imputation automatically; users who want to mirror Han 2016’s missing-handling should pre-fill missing ALB with 41.8 g/L and missing ALP with 76.3 U/L on the input data table.
- Reference covariate values: Han 2016 Methods page 343 says the continuous-covariate reference value is “the median of the covariate for all patients” but uses 70 kg (rather than the model-building median 74.8 kg) for BWT. The model file follows the paper: BWT reference 70 kg, ALB reference 39 g/L (median), ALP reference 109 U/L (median), matching Han 2016 Figure 2 typical-patient caption.
-
Categorical covariate encoding: Han 2016 reports
Male and IFN-alpha effects as e^theta multiplicative factors (1.14,
1.18, 0.844 on CL/V1/CL). The model file encodes the log-effect
parameters
e_male_lcl,e_male_lvc,e_ifna_lclso the model() block can writeexp(theta * indicator). The Male indicator is derived from the canonical SEXF column asmale = 1 - SEXF; the IFN-alpha indicator uses the canonical CONMED_IFNALPHA column. - Erratum search: A search of PubMed and the Springer article landing page on 2026-06-25 returned no erratum, corrigendum, or author correction for doi:10.1007/s00280-016-3079-6. All values are taken from the original 2016 publication.
- External validation cohort excluded: The 146 Japanese patients in studies JO18157, JO19901, and JO19907 (1670 concentrations) were used only for external validation in Han 2016 and were not part of the parameter estimation. Their concentrations are not available to this vignette.
Reference
- Han K, Peyret T, Marchand M, Quartino A, Gosselin NH, Girish S, Allison DE, Jin J. Population pharmacokinetics of bevacizumab in cancer patients with external validation. Cancer Chemother Pharmacol. 2016;78(2):341-351. doi:10.1007/s00280-016-3079-6