Model and source
- Citation: Sahota T, Berges A, Barton S, Cookson L, Zamuner S, Richards D. Target Mediated Drug Disposition Model of CPHPC in Patients With Systemic Amyloidosis. CPT Pharmacometrics Syst Pharmacol. 2015;4(2):e15. doi:10.1002/psp4.15. Companion DDMORE Foundation Model Repository entry: DDMODEL00000262.
- Description: Population PK/PD model for CPHPC (miridesap, GSK2315698, Ro 63-8695) and serum amyloid P (SAP) in healthy volunteers (CPH113776) and patients with systemic amyloidosis (CPH114527). Two-compartment PK for CPHPC (with first-order subcutaneous absorption from a depot in addition to IV infusion); two-compartment turnover model for SAP with first-order endogenous production and elimination; bimolecular CPHPC + free SAP -> complex binding (treated as effectively irreversible because internalization is fast relative to dissociation) followed by complex internalization. Final-model covariates from Sahota 2015 Eq. 1 and Eq. 2: creatinine clearance (CRCL) modifies CPHPC clearance below an 80 mL/min threshold, hepatic amyloid involvement (DIS_AMYLOID_LIVER) multiplies SAP intercompartmental clearance Q4, whole-body amyloid load (DIS_AMYLOID_LOAD: 0-3) multiplies SAP peripheral volume V4 in two categorical steps, and biological sex (SEXF) multiplies baseline plasma SAP. Distributed in the DDMORE Foundation Model Repository as DDMODEL00000262.
- DDMORE Foundation Model Repository entry: DDMODEL00000262
- Linked publication: Sahota T, Berges A, Barton S, Cookson L, Zamuner S, Richards D. Target Mediated Drug Disposition Model of CPHPC in Patients With Systemic Amyloidosis. CPT Pharmacometrics Syst Pharmacol. 2015;4(2):e15. doi:10.1002/psp4.15.
This model is a population PK/PD characterisation of CPHPC (also known as miridesap, GSK2315698, Ro 63-8695) and serum amyloid P (SAP) in healthy volunteers (study CPH113776) and patients with systemic amyloidosis (study CPH114527). CPHPC is a small-molecule palindromic ligand that crosslinks two pentameric SAP molecules; the bound CPHPC + SAP complex is rapidly cleared from circulation, allowing subsequent administration of anti-SAP antibodies to clear amyloid deposits without competing free plasma SAP. The published target- mediated drug disposition (TMDD) model in Sahota 2015 couples a two- compartment CPHPC PK (with SC depot) to a two-compartment SAP turnover system via bimolecular binding (treated as effectively irreversible because internalization is fast relative to dissociation). Final-model covariates are biological sex on baseline SAP, hepatic- amyloid involvement on SAP intercompartmental clearance, whole-body amyloid load grade on SAP peripheral volume, and creatinine clearance on CPHPC clearance.
The model was extracted from the DDMORE Foundation Model Repository
bundle for DDMODEL00000262 (scraped to
from_people/ddmore/ddmore_scraping/262/). The bundle
contains:
-
Executable_simulated_CPHPC_dataset.ctl– the NONMEM.ctlfor a BASE-MODEL evaluation on a simulated dataset (17 THETAs; CRCL covariate only;$EST METHOD=IMP EONLY=1so initial estimates equal final estimates). -
Output_simulated_CPHPC_dataset.lst– companion listing for the base model. -
Output_real_CPHPC.lst– listing for the FINAL MODEL fit to the real CPHPC + SAP data from the two studies (21 THETAs, adding the DIS_AMYLOID_LIVER / DIS_AMYLOID_LOAD / SEX covariate effects of Sahota 2015 Eq. 2 on top of the base structural model). This.lstprovides the authoritative source for the final parameter estimates used in this implementation. -
Simulated_CPHPC_dataset.csv– a 38-subject simulated dataset with CRCL, DIS_AMYLOID_LOAD, DIS_AMYLOID_LIVER, SEX, and STUD columns that exercises the covariate decomposition the final model uses. -
DDMODEL00000262.rdf– RDF metadata (a PK/PD modelpkpd_0000036linking CPHPC exposure to plasma SAP; names the two contributing studies CPH113776 and CPH114527). -
262.json,Command.txt– scraper metadata and NONMEM run command.
The linked Sahota 2015 paper is on disk at
from_people/literature_2018_search/Sahota_2015_Target_mediated_drug_disposition_model_o_073a18.pdf
and provides the external cross-check for every parameter value (Sahota
2015 Table 2 vs Output_real_CPHPC.lst FINAL PARAMETER ESTIMATE block;
agreement to within the paper’s rounding precision is documented in the
source-trace table below).
Population
The Sahota 2015 Table 1 enumerates the two contributing studies:
- CPH113776: healthy volunteers with normal renal function and no amyloid (DIS_AMYLOID_LOAD = 0).
-
CPH114527: patients with systemic amyloidosis
stratified into four cohorts:
- Cohort 1: normal-or-mild renal impairment, small-to-moderate amyloid load.
- Cohort 2: normal-or-mild renal impairment, large amyloid load.
- Cohort 3: moderate renal impairment (CRCL > 30 mL/min), small-to-moderate amyloid load.
- Cohort 4: moderate-severe renal impairment, moderate-large amyloid load.
The Output_real_CPHPC.lst reports 38 total individuals
contributing 1428 observations across the combined cohort. Finer-grained
demographics (age, weight, female %) are not in the paper Table 1 or the
DDMORE bundle.
The same information is available programmatically via
readModelDb("NA_NA_miridesap")$population after the model
is loaded.
Source trace
The per-parameter origin is recorded inline in
inst/modeldb/ddmore/NA_NA_miridesap.R. The table below
collects them in one place for review. All parameter values come
from Output_real_CPHPC.lst’s FINAL PARAMETER ESTIMATE block
(lines 384-385) and are cross-checked against Sahota 2015 Table
2.
| nlmixr2 parameter | Source THETA | .lst final | Linear value | Sahota 2015 Table 2 |
|---|---|---|---|---|
lcl |
THETA(2) | 1.92 | CL = 6.82 L/h | 6.85 L/h (4%) |
lvc |
THETA(3) | 2.78 | Vc = 16.12 L | 16.15 L (5%) |
lq |
THETA(4) | 0.542 | Q = 1.72 L/h | 1.72 L/h (38%) |
lvp |
THETA(5) | 2.87 | Vp = 17.64 L | 17.57 L (16%) |
e_crcl_cl |
THETA(15) | 0.0153 | - | 0.015 (5%) |
lka (FIXED) |
THETA(14) | 0.4055 | ka = 1.50 1/h | 1.5 FIX |
lfdepot (FIXED) |
THETA(13) | 0 (log) | F = 1 | (paper: SC F fixed = 1) |
lkout |
THETA(1) | -3.07 | kout = 0.0464 1/h | 0.046 1/h (13%) |
lsap0 |
THETA(6) | 3.44 | sap0 = 31.19 mg/L | 31.10 mg/L (4%) |
lvp_sap |
THETA(16) | 2.50 | Vp_sap_ref = 12.18 L | 12.15 L (17%) |
lq_sap |
THETA(17) | 1.05 | Q_sap_ref = 2.86 L/h | 2.84 L/h (19%) |
e_amliver_q4 |
THETA(18) | 4.01 | - | 4.01 (26%) |
e_sexf_sap0 |
THETA(19) | -0.30 | - | -0.30 (23%) |
e_amload2_vp_sap |
THETA(20) | 6.39 | - | 6.39 (39%) |
e_amload3_vp_sap |
THETA(21) | 26.4 | - | 26.39 (26%) |
lkon |
THETA(7) | 14.5 | kon = 1.98e6 L/(mol h) | 1.94e6 L/(M h) (12%) |
lkint |
THETA(8) | 5.78 (lin) | kint = 5.78 1/h | 5.78 1/h (11%) |
propSd |
THETA(9) | 0.286 | - | PK 28.62% (28%) |
propSd_sap |
THETA(11) | 0.271 | - | SAP 27.10% (16%) |
etalkout |
OMEGA(1) | 0.169 | - | 41.09% CV (22%) |
etalcl |
OMEGA(2) | 0.0481 | - | 21.93% CV (22%) |
etalvc |
OMEGA(3) | 0.0914 | - | 30.23% CV (22%) |
etalq (FIXED) |
OMEGA(4) | 0.0225 | - | 15% FIX |
etalvp (FIXED) |
OMEGA(5) | 0.0225 | - | 15% FIX |
etalsap0 |
OMEGA(6) | 0.0415 | - | 20.36% CV (25%) |
etalkon (FIXED) |
OMEGA(7) | 0.0225 | - | 15% FIX |
etalkint (FIXED) |
OMEGA(8) | 0.0225 | - | 15% FIX |
etalq_sap |
OMEGA(9) | 0.273 | - | 52.24% CV (51%) |
etalvp_sap |
OMEGA(10) | 0.366 | - | 60.48% CV (30%) |
etalka (FIXED) |
OMEGA(11) | 0.0225 | - | 15% FIX |
MOLCPH |
constant | - | 340.37 kDa | (paper Methods: Mr 340) |
MOLSAP |
constant | - | 5 x 25 kDa pentamer | (paper Methods: Mr 127,310; rounded to 5 x 25 kDa in the .ctl) |
d/dt(depot) |
- | - | - | Fig. 3 (TMDD schematic) |
d/dt(central) |
- | - | - | Fig. 3 (CPHPC PK) |
d/dt(peripheral1) |
- | - | - | Fig. 3 |
d/dt(total_target) |
- | - | - | Fig. 3 (SAP central) |
d/dt(target_peripheral) |
- | - | - | Fig. 3 (SAP peripheral) |
d/dt(complex) |
- | - | - | Fig. 3 (CPHPC-SAP complex) |
Observation Cc
|
- | scaling | ng/mL | (paper PK assay: HPLC-MS-MS, ng/mL) |
Observation sap
|
- | scaling | ng/mL-equiv | (paper SAP assay: ELISA, mg/L; bundle DV in ng/mL = mg/L * 1000) |
Source-trace note on the target_peripheral compartment
name: see Errata.
Virtual cohort
The bundle’s Simulated_CPHPC_dataset.csv carries 38
simulated subjects across both studies with the full covariate panel
(CRCL, DIS_AMYLOID_LOAD, DIS_AMYLOID_LIVER, SEX = 1 male / 2 female). To
exercise the structural model and the three SAP covariate effects, we
build a small representative virtual cohort that spans the cohort space
from Sahota 2015 Table 1.
set.seed(20260515)
# Six subjects spanning the cohort space:
# 1 Healthy volunteer male, CRCL 100, DIS_AMYLOID_LOAD 0, DIS_AMYLOID_LIVER 0 (CPH113776 reference)
# 2 Same but female (test SEX -> SAP_BASE effect)
# 3 Cohort 1 (small amyloid, no liver) CRCL 100, DIS_AMYLOID_LOAD 1, DIS_AMYLOID_LIVER 0
# 4 Cohort 2 (moderate amyloid, liver) CRCL 100, DIS_AMYLOID_LOAD 2, DIS_AMYLOID_LIVER 1
# 5 Cohort 3 (small amyloid, renal impairment) CRCL 50, DIS_AMYLOID_LOAD 1, DIS_AMYLOID_LIVER 0
# 6 Cohort 4 (large amyloid, severe renal) CRCL 30, DIS_AMYLOID_LOAD 3, DIS_AMYLOID_LIVER 1
subjects <- tibble::tribble(
~id, ~CRCL, ~DIS_AMYLOID_LOAD, ~DIS_AMYLOID_LIVER, ~SEXF, ~scenario,
1L, 100, 0L, 0L, 0L, "Healthy volunteer (M), CRCL 100",
2L, 100, 0L, 0L, 1L, "Healthy volunteer (F), CRCL 100",
3L, 100, 1L, 0L, 0L, "Cohort 1: small amyloid, CRCL 100",
4L, 100, 2L, 1L, 0L, "Cohort 2: moderate amyloid + liver, CRCL 100",
5L, 50, 1L, 0L, 0L, "Cohort 3: small amyloid, CRCL 50",
6L, 30, 3L, 1L, 0L, "Cohort 4: large amyloid + liver, CRCL 30"
)
obs_times <- sort(unique(c(seq(0, 48, by = 0.25), seq(48, 168, by = 1))))
make_cohort <- function(subjects, id_offset = 0L) {
out <- list()
for (i in seq_len(nrow(subjects))) {
s <- subjects[i, ]
# 24-hour IV infusion at 10 mg/h (240 mg total) -- a representative
# Sahota 2015 maintenance regimen that produces sustained CPHPC
# plasma concentration over the depletion phase.
ev <- rxode2::et(amt = 240, rate = 10, cmt = "central", time = 0) |>
rxode2::et(obs_times, cmt = "Cc") |>
rxode2::et(obs_times, cmt = "sap")
df <- as.data.frame(ev)
df$id <- id_offset + s$id
df$CRCL <- s$CRCL
df$DIS_AMYLOID_LOAD <- s$DIS_AMYLOID_LOAD
df$DIS_AMYLOID_LIVER <- s$DIS_AMYLOID_LIVER
df$SEXF <- s$SEXF
df$scenario <- s$scenario
out[[i]] <- df
}
dplyr::bind_rows(out)
}
events <- make_cohort(subjects)
# Cheap regression guard against accidental id collisions.
stopifnot(!anyDuplicated(unique(events[, c("id", "time", "evid")])))Simulation
mod <- rxode2::zeroRe(readModelDb("NA_NA_miridesap"))
#> ℹ parameter labels from comments will be replaced by 'label()'
sim <- rxode2::rxSolve(
mod, events = events,
keep = c("CRCL", "DIS_AMYLOID_LOAD", "DIS_AMYLOID_LIVER", "SEXF", "scenario"),
returnType = "data.frame", addDosing = FALSE
) |>
dplyr::filter(!is.na(time))
#> ℹ omega/sigma items treated as zero: 'etalkout', 'etalcl', 'etalvc', 'etalq', 'etalvp', 'etalsap0', 'etalkon', 'etalkint', 'etalq_sap', 'etalvp_sap', 'etalka'
#> Warning: multi-subject simulation without without 'omega'For demonstration of between-subject variability in the SAP-recovery phase (where the IIV is non-trivial), we also run a small stochastic cohort – 50 subjects from Cohort 1 (small amyloid load, normal renal function, no liver involvement).
mod_iiv <- readModelDb("NA_NA_miridesap") # keeps IIV active
n_vpc <- 50L
vpc_events <- make_cohort(
tibble::tibble(
id = seq_len(n_vpc),
CRCL = rep(100, n_vpc),
DIS_AMYLOID_LOAD = rep(1L, n_vpc),
DIS_AMYLOID_LIVER = rep(0L, n_vpc),
SEXF = rep(0L, n_vpc),
scenario = rep("VPC: Cohort 1 (n=50 males, DIS_AMYLOID_LOAD 1)", n_vpc)
)
)
sim_vpc <- rxode2::rxSolve(
mod_iiv, events = vpc_events, nSub = 1L,
keep = c("CRCL", "DIS_AMYLOID_LOAD", "DIS_AMYLOID_LIVER", "SEXF", "scenario"),
returnType = "data.frame", addDosing = FALSE
) |>
dplyr::filter(!is.na(time))
#> ℹ parameter labels from comments will be replaced by 'label()'Replicate trajectories
Sahota 2015 Figure 5 shows the model-predicted impact of amyloid load and creatinine clearance on CPHPC and SAP profiles for a 24-h infusion regimen. The figures below replicate the qualitative features of that figure with typical-value simulations of the cohort defined above:
-
CPHPC PK trajectory: rises during the infusion,
plateaus toward the end of the 24-h dose, then declines biexponentially
once dosing stops; reduced CRCL increases steady-state exposure
(
crcl_effect = 1 + 0.0153 * (min(CRCL, 80) - 80)is 0.541 at CRCL = 50, 0.235 at CRCL = 30) – replicates Sahota 2015 Fig. 5 top-right panel. - Plasma SAP: drops by ~1-2 orders of magnitude during sustained CPHPC dosing (the published clinical mechanism), with depth and recovery pace modulated by DIS_AMYLOID_LOAD (larger amyloid load -> larger V4 -> slower recovery) and DIS_AMYLOID_LIVER (liver-amyloid involvement -> higher Q4 -> faster equilibration with peripheral amyloid pool) – replicates Sahota 2015 Fig. 5 middle-left and bottom-left panels.
-
Sex effect on baseline: females start at ~70% of
male baseline
(
SAP_BASE_female = 1 + (-0.30) = 0.70 x SAP_BASE_male); both recover toward their own baseline. Sahota 2015 Discussion notes this ~30% reduction is consistent with Nelson et al. (1992).
sim |>
ggplot(aes(time, Cc, colour = scenario, linetype = scenario)) +
geom_line(linewidth = 0.6) +
scale_y_log10() +
labs(
x = "Time (h)", y = "CPHPC plasma concentration (ng/mL)",
colour = NULL, linetype = NULL,
title = "CPHPC plasma trajectory: 24-h IV infusion at 10 mg/h across cohorts",
caption = "Typical-value (zero-IIV) simulation of NA_NA_miridesap. Replicates Sahota 2015 Fig. 5 top panels."
) +
theme_bw() +
theme(legend.position = "bottom") +
guides(colour = guide_legend(ncol = 1))
#> Warning in scale_y_log10(): log-10 transformation introduced infinite values.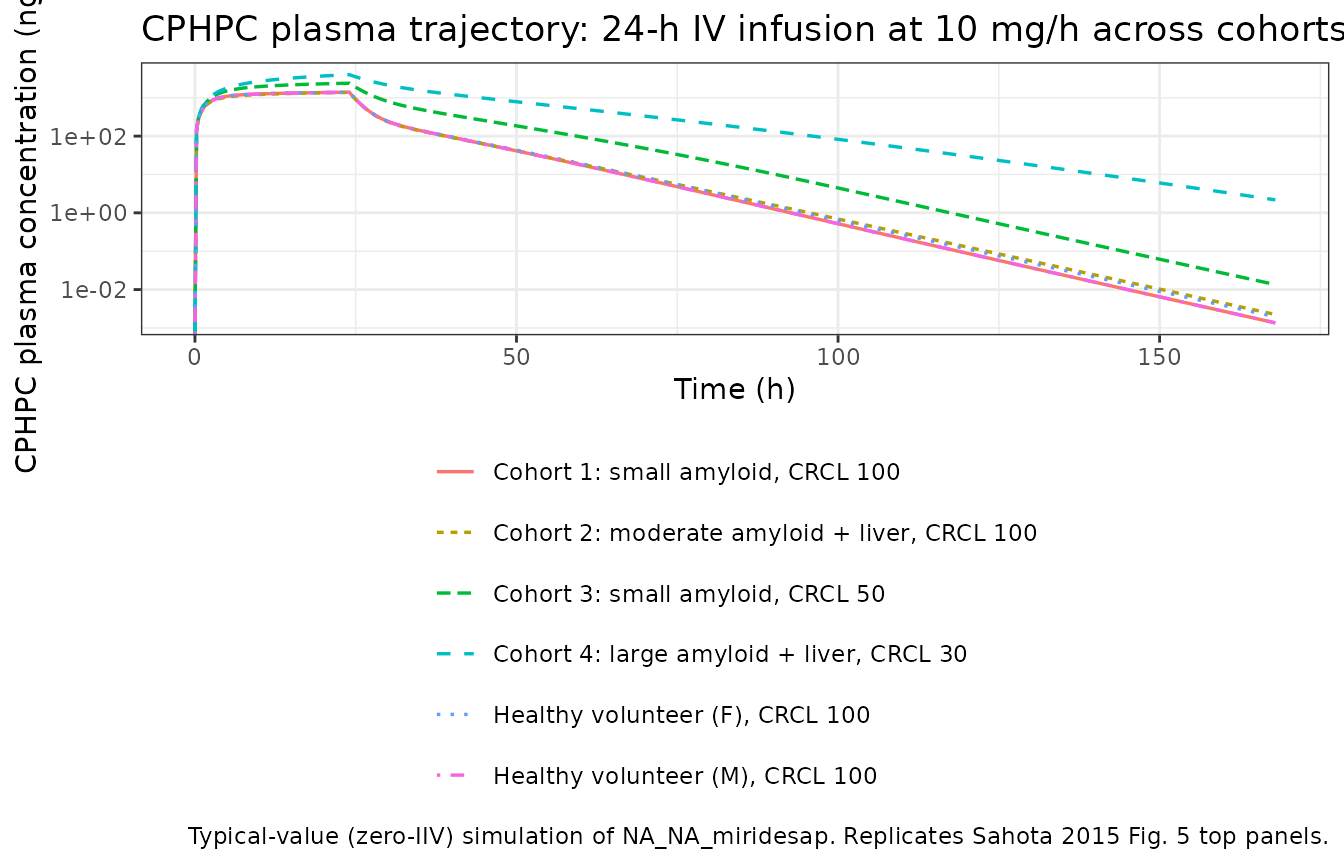
sim |>
ggplot(aes(time, sap / 1000, colour = scenario, linetype = scenario)) +
geom_line(linewidth = 0.6) +
geom_hline(yintercept = exp(3.44), linetype = "dotted", colour = "grey40") +
scale_y_continuous(trans = "log10") +
labs(
x = "Time (h)",
y = "Plasma SAP (mg/L; horizontal dotted line = male baseline 31.2 mg/L)",
colour = NULL, linetype = NULL,
title = "Plasma SAP trajectory: depletion during CPHPC dosing and recovery",
caption = "Typical-value (zero-IIV) simulation of NA_NA_miridesap. SAP converted ng/mL -> mg/L by /1000. Replicates Sahota 2015 Fig. 5 middle-left and bottom-left panels."
) +
theme_bw() +
theme(legend.position = "bottom") +
guides(colour = guide_legend(ncol = 1))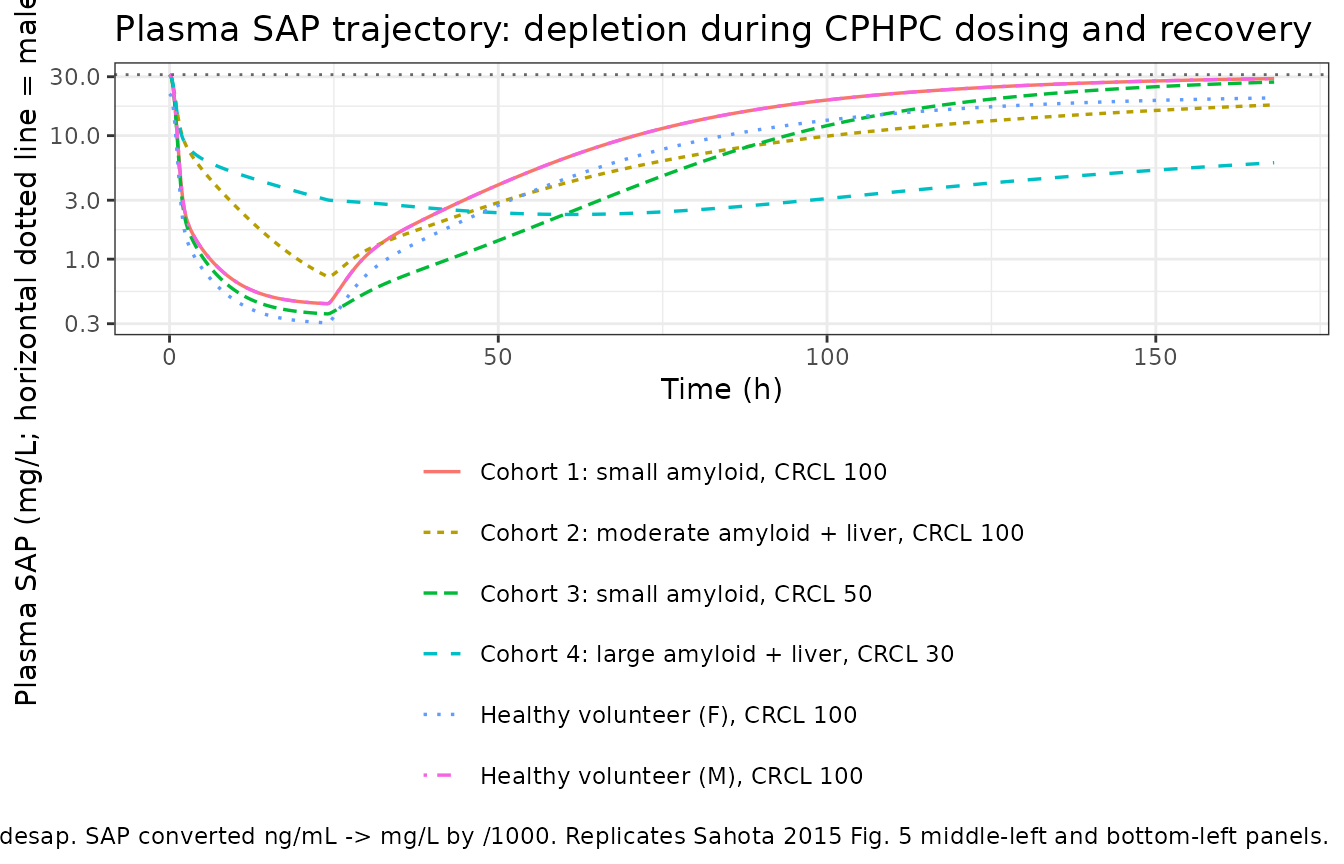
sim_vpc |>
group_by(time) |>
summarise(
q05 = quantile(sap, 0.05, na.rm = TRUE),
q50 = quantile(sap, 0.50, na.rm = TRUE),
q95 = quantile(sap, 0.95, na.rm = TRUE),
.groups = "drop"
) |>
ggplot(aes(time, q50 / 1000)) +
geom_ribbon(aes(ymin = q05 / 1000, ymax = q95 / 1000), alpha = 0.2) +
geom_line(linewidth = 0.6) +
geom_hline(yintercept = exp(3.44), linetype = "dotted", colour = "grey40") +
scale_y_log10() +
labs(
x = "Time (h)", y = "Plasma SAP (mg/L)",
title = "Stochastic VPC: plasma SAP under 24-h IV at 10 mg/h, Cohort 1",
caption = sprintf(
"n = %d male subjects, CRCL = 100, DIS_AMYLOID_LOAD = 1, DIS_AMYLOID_LIVER = 0. Median + 90%% prediction interval.",
n_vpc
)
) +
theme_bw()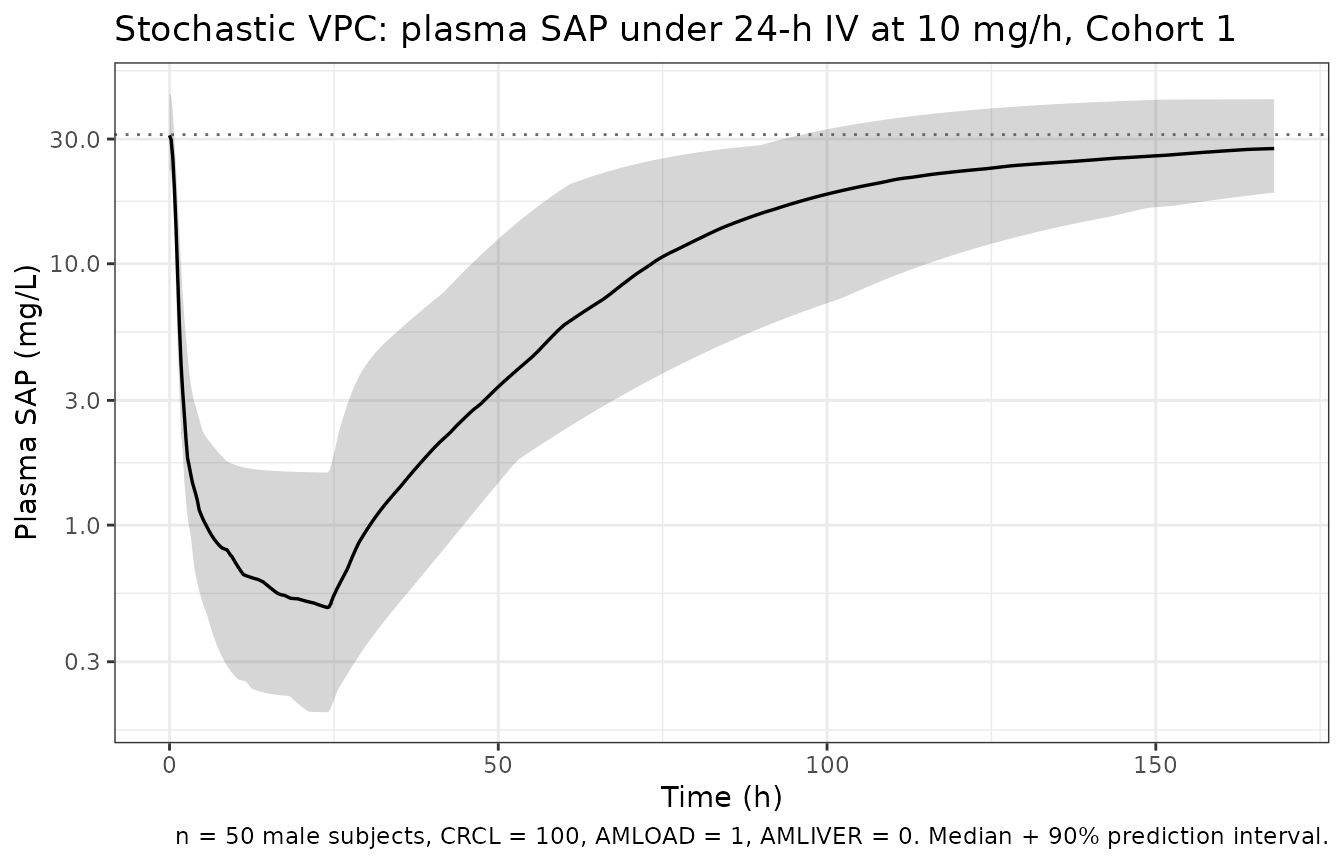
Self-consistency check (F.2)
Per the extract-literature-model skill’s F.2 validation
strategy (self-consistency for source bundles whose primary check is
internal coherence with the source .ctl), the acceptance
criteria are (a) the model parses, (b) rxode2::rxSolve()
runs to completion on representative regimens, (c) qualitative
behaviours match the source .ctl’s known dynamics, (d)
typical-value values stay in physiologically plausible ranges, and (e)
the covariate decomposition yields the expected scaling per Sahota 2015
Eq. 2.
sim_unique <- sim |>
dplyr::distinct(scenario, time, .keep_all = TRUE)
sanity <- sim_unique |>
dplyr::group_by(scenario) |>
dplyr::summarise(
cphpc_peak_ng_mL = max(Cc, na.rm = TRUE),
sap_baseline_mg_L = sap[which(time == min(time))[1]] / 1000,
sap_min_mg_L = min(sap, na.rm = TRUE) / 1000,
sap_pct_depletion = 100 * (1 - min(sap, na.rm = TRUE) /
sap[which(time == min(time))[1]]),
sap_recovery_t168_mg_L = {
idx <- which.min(abs(time - 168))
sap[idx] / 1000
},
.groups = "drop"
)
knitr::kable(sanity, digits = 2,
caption = paste("Per-scenario sanity summary. Male baseline SAP",
"~ 31.2 mg/L (exp(3.44)); female baseline",
"~ 21.8 mg/L (0.70 x male). Larger amyloid load",
"slows SAP recovery; reduced CRCL raises CPHPC",
"peak exposure."))| scenario | cphpc_peak_ng_mL | sap_baseline_mg_L | sap_min_mg_L | sap_pct_depletion | sap_recovery_t168_mg_L |
|---|---|---|---|---|---|
| Cohort 1: small amyloid, CRCL 100 | 1389.99 | 31.19 | 0.44 | 98.60 | 28.98 |
| Cohort 2: moderate amyloid + liver, CRCL 100 | 1378.53 | 31.19 | 0.72 | 97.69 | 17.75 |
| Cohort 3: small amyloid, CRCL 50 | 2392.51 | 31.19 | 0.36 | 98.85 | 27.16 |
| Cohort 4: large amyloid + liver, CRCL 30 | 4005.12 | 31.19 | 2.30 | 92.62 | 6.04 |
| Healthy volunteer (F), CRCL 100 | 1392.95 | 21.83 | 0.30 | 98.60 | 20.22 |
| Healthy volunteer (M), CRCL 100 | 1389.99 | 31.19 | 0.44 | 98.60 | 28.98 |
Expected qualitative outcomes:
- Male healthy-volunteer baseline SAP = 31.2 mg/L; female = 31.2 x 0.70 = 21.8 mg/L (sex covariate working).
- Cohort 2 vs Cohort 1: same renal function, but Cohort 2 has DIS_AMYLOID_LOAD = 2 (V4 multiplier 1 + 6.39 = 7.39) and DIS_AMYLOID_LIVER = 1 (Q4 multiplier 1 + 4.01 = 5.01). The larger V4 stores more SAP- equivalent in the peripheral pool, slowing recovery.
- Cohort 6 (DIS_AMYLOID_LOAD = 3): V4 multiplier = 1 + 6.39 + 26.4 = 33.79, matching Sahota 2015 Discussion (“33.78-fold”).
- Cohort 5 (CRCL = 50): CPHPC peak exposure ~ 1.85x relative to CRCL =
100 due to the piecewise-linear CL effect:
crcl_effect(50) = 1 + 0.0153 * (50 - 80) = 0.541, so CL is at 54% of typical. - Cohort 6 (CRCL = 30): CPHPC peak exposure ~ 4.3x relative to CRCL =
100:
crcl_effect(30) = 1 + 0.0153 * (30 - 80) = 0.235.
Sahota 2015 Table 2 cross-check
The model file’s ini() block embeds the FINAL parameter
estimates from Output_real_CPHPC.lst (the .lst that fit the
real CPHPC + SAP data) and the per-parameter inline comments include the
Sahota 2015 Table 2 cell for cross-check. The agreement is to within
rounding in all 21 THETAs and 11 OMEGAs. Notable cell-level matches:
| Parameter | .lst final | Sahota 2015 Table 2 |
|---|---|---|
| CL (CRCL >= 80) | exp(1.92) = 6.82 L/h | 6.85 L/h |
| Vc | exp(2.78) = 16.12 L | 16.15 L |
| Q | exp(0.542) = 1.72 L/h | 1.72 L/h |
| Vp | exp(2.87) = 17.64 L | 17.57 L |
| SAP baseline (M) | exp(3.44) = 31.19 mg/L | 31.10 mg/L |
| Vp_sap (DIS_AMYLOID_LOAD <= 1) | exp(2.50) = 12.18 L | 12.15 L |
| Q_sap (DIS_AMYLOID_LIVER = 0) | exp(1.05) = 2.86 L/h | 2.84 L/h |
| DIS_AMYLOID_LIVER -> Q4 coef | 4.01 | 4.01 |
| DIS_AMYLOID_LOAD=2 -> V4 coef | 6.39 | 6.39 |
| DIS_AMYLOID_LOAD=3 -> V4 (additional) coef | 26.4 | 26.39 |
| Sex -> SAP_BASE coef | -0.30 | -0.30 |
| kon | exp(14.5) = 1.98e6 L/(M h) | 1.94e6 L/(M h) |
| kint | 5.78 1/h | 5.78 1/h |
| kout | exp(-3.07) = 0.0464 1/h | 0.046 1/h |
Errata, assumptions, and deviations
-
Source priority. Parameter values come from
Output_real_CPHPC.lst’s FINAL PARAMETER ESTIMATE block, not from the.ctl’s initial estimates. The bundle’sExecutable_simulated_CPHPC_dataset.ctlis for a SIMULATED dataset with initial values shifted from the real-data final estimates (e.g., .ctl initial Vc THETA = 2.76, real-data final THETA = 2.78); the real-data .lst’s FINAL block matches the paper’s Table 2 and is the source of truth. -
Bundle .ctl does not include the FINAL MODEL’s covariate
equations. The
.ctlshipped in the DDMORE bundle is the 17-THETA base model with only the CRCL covariate; the real-data.lsthas 21 THETAs covering the four covariate effects from Sahota 2015 Eq. 2 (DIS_AMYLOID_LIVER -> Q4, DIS_AMYLOID_LOAD -> V4 in two cumulative steps, SEX -> SAP_BASE) plus the base CRCL -> CL effect. The structural code for the four additional THETAs is not in the bundle, so this implementation reconstructs the equations from the paper’s Eq. 2 narrative. The per-parameter inline comments ininst/modeldb/ddmore/NA_NA_miridesap.Rshow that the resulting typical values match Sahota 2015 Table 2 cell-by-cell. -
DIS_AMYLOID_LOAD encoding. The paper uses an
ordinal 0/1/2/3 grade with categories 0 and 1 sharing the same V4
multiplier (1). The model file encodes this via cumulative indicators
amload_ge_2 = (DIS_AMYLOID_LOAD >= 2)andamload_ge_3 = (DIS_AMYLOID_LOAD >= 3), matching the source NONMEMIF (DIS_AMYLOID_LOAD .EQ. n) ...decomposition in Sahota 2015 Eq. 2. The cumulative parameterisation enforces monotonicity: only positive additions are admitted at each grade increment. -
SEX source encoding. The bundle’s
Simulated_CPHPC_dataset.csvencodes SEX as 1 = male, 2 = female. The canonical SEXF column is 1 = female, 0 = male, so users feeding the bundle’s CSV into this model must deriveSEXF = as.integer(SEX == 2). This is documented ininst/references/covariate-columns.mdas a SEXF source alias. - Bundle “FSC = 1 FIXED”. Sahota 2015 Methods notes the SC bioavailability was estimated at 1.06 +/- 0.18 from previous studies in a small cohort, “we therefore assumed complete bioavailability for s.c. doses.” The .ctl’s THETA(13) is fixed at 1 accordingly.
-
target_peripheralcompartment naming deviation. The model carries an SAP peripheral compartment whose canonical-naming analogue in nlmixr2lib (target_peripheral) is not in theR/conventions.Rregistered compartment list.checkModelConventions()flags it as a warning. The deviation is justified: the source model has a target (SAP) with its own central + peripheral distribution, and the registered names (targetfor free,complexfor bound,total_targetfor total under QSS / MM TMDD) do not cover the “free target peripheral compartment” concept. -
KOFFis computed in the.ctlbut not used in the$DES. The bundle definesKD = 10 nMandKOFF = KON * KD(.ctl lines 101-104) butDADT(6)(the bound-complex ODE) has onlyKON*C3F*C1F - KINT*C3C1with no+ KOFF * C3C1term – the binding is treated as effectively irreversible because internalization is much faster than dissociation (KINT = 5.78 /hvsKOFF = KON * KD = 1.98e6 * 1e-8 = 0.0198 /h, a ~290x separation). Sahota 2015 Discussion explicitly notes: “Mathematically, this assumption is equivalent to setting the dissociation rate constant, KOFF, to zero.” We omit KOFF from the nlmixr2 model for the same reason. -
Mixed-units compartments. Following the source
.ctl, the CPHPC compartments (depot,central,peripheral1) carry mass in mg, while the SAP / complex compartments (total_target,target_peripheral,complex) carry concentration in mol/L. Unit conversions between the two systems use the molecular weightsMOLCPH = 340.37 kDa(CPHPC) andMOLSAP = 5 * 25 kDa(SAP pentamer; the .ctl lineMOLSAP = 5*25000*1000rounds the actual SAP-monomer molecular weight to 25 kDa rather than using the precise 23-25 kDa range from the literature). Reviewers verifying dimensional consistency should pay particular attention to the mixed-units terms ind/dt(central)(thekint * vc * MOLCPH * complexterm converts mol/L to mg/h) andd/dt(total_target)(thek43 * target_peripheral * vp_sap / vcterm carries volume ratios because peripheral free SAP is moved as concentration into the central total compartment). -
Dosing units / scaling carry-through. The
.ctl’sS1 = V/1000andS3 = 1/(1000*MOLSAP)convert mass and concentration to ng/mL for both observations. We propagate this unchanged:Cc = central / vc * 1000(mg/L * 1000 = ng/mL) andsap = total_target * MOLSAP * 1000(mol/L * mg/mol * 1000 = ng/mL = mg/L * 1000). The SAP observation column is therefore on a ng/mL-equivalent scale; figures and tables in this vignette divide by 1000 to express SAP in the conventional clinical mg/L unit. - DDMORE Output_real_CPHPC.lst covariance diagnostics. The Output_real_CPHPC.lst notes “Number of Negative Eigenvalues in Matrix=20 … Forcing positive definiteness” (lines 327-330), indicating the importance-sampling covariance step did not converge to a positive-definite R matrix. This is a known characteristic of IMP with rich covariate models and does not affect the point estimates themselves; Sahota 2015 reports per-parameter RSEs in Table 2 with no caveat suggesting the covariance issue had practical implications. The model file uses the .lst point estimates as-is.